

DALL·E 2 คือปัญญาประดิษฐ์ที่สร้างโดยบริษัทวิจัยทางด้านปัญญาประดิษฐ์ Open AI ที่เคยมีเศรษฐีอย่าง Elon Musk เคยเป็นผู้ร่วมก่อตั้ง
 เขียนโดย
เขียนโดย
Waranyu Khongchai
Internship @ borntoDev
 DALL·E 2 เป็นเวอร์ชันอัพเกรดที่มีการพัฒนาจาก DALL·E รุ่นแรกที่เปิดตัวปีที่แล้ว โดยความสามารถของ DALL·E 2 คือ สามารถสร้างรูปภาพจากคำบรรยายที่เป็นภาษาธรรมชาติ คุณสมบัติที่อัพเกรดจากเวอร์ชันแรกคือแก้ไขภาพต้นฉบับ โดยการแก้ไขคือสามารถเติมวัตถุภายในภาพ และกำหนดตำแหน่งที่ต้องการแก้ไขตามคำบรยาย อีกอย่างของความสามารถที่อัพเกรดคือสร้างภาพที่มีความละเอียดสูงได้
DALL·E 2 เป็นเวอร์ชันอัพเกรดที่มีการพัฒนาจาก DALL·E รุ่นแรกที่เปิดตัวปีที่แล้ว โดยความสามารถของ DALL·E 2 คือ สามารถสร้างรูปภาพจากคำบรรยายที่เป็นภาษาธรรมชาติ คุณสมบัติที่อัพเกรดจากเวอร์ชันแรกคือแก้ไขภาพต้นฉบับ โดยการแก้ไขคือสามารถเติมวัตถุภายในภาพ และกำหนดตำแหน่งที่ต้องการแก้ไขตามคำบรยาย อีกอย่างของความสามารถที่อัพเกรดคือสร้างภาพที่มีความละเอียดสูงได้
จุดประสงค์ของ DALL·E 2

แปลไทยคือ “ DALL·E 2 สามารถสร้างภาพและงานศิลปะที่เป็นต้นฉบับ และสมจริงได้จากคำอธิบายข้อความ สามารถรวมแนวคิด, คุณลักษณะ และสไตล์เข้าด้วยกัน ”
แล้ว DALL·E 2 ตัวนี้มีหลักการการทำงานอย่างไร โดยในบทความนี้จะมาอธิบายให้เข้าใจให้อย่างง่ายที่สุด DALL·E 2 มีหลักการทำงานแบบอย่างง่าย ๆ 3 ข้อคือ
-
ป้อนข้อความเข้าไปในตัวเข้ารหัสข้อความ
-
แบบจำลองข้อความไปจับคู่ระหว่าง Encrypt message และ Encode picture โดยการใช้การรวบรวมเชิงความหมายจากข้อมูลข้อความ
-
ตัวถอดรหัสข้อความนำข้อมูลที่ได้จากแบบจำลองข้อความไปสร้างรูปภาพโดยการสุ่ม
แน่นอนว่าก็ยังมีรายละเอียดเบื้องลึกเทคโนโลยีการทำงานที่มาเสริม DALL·E 2 ดังต่อไปนี้
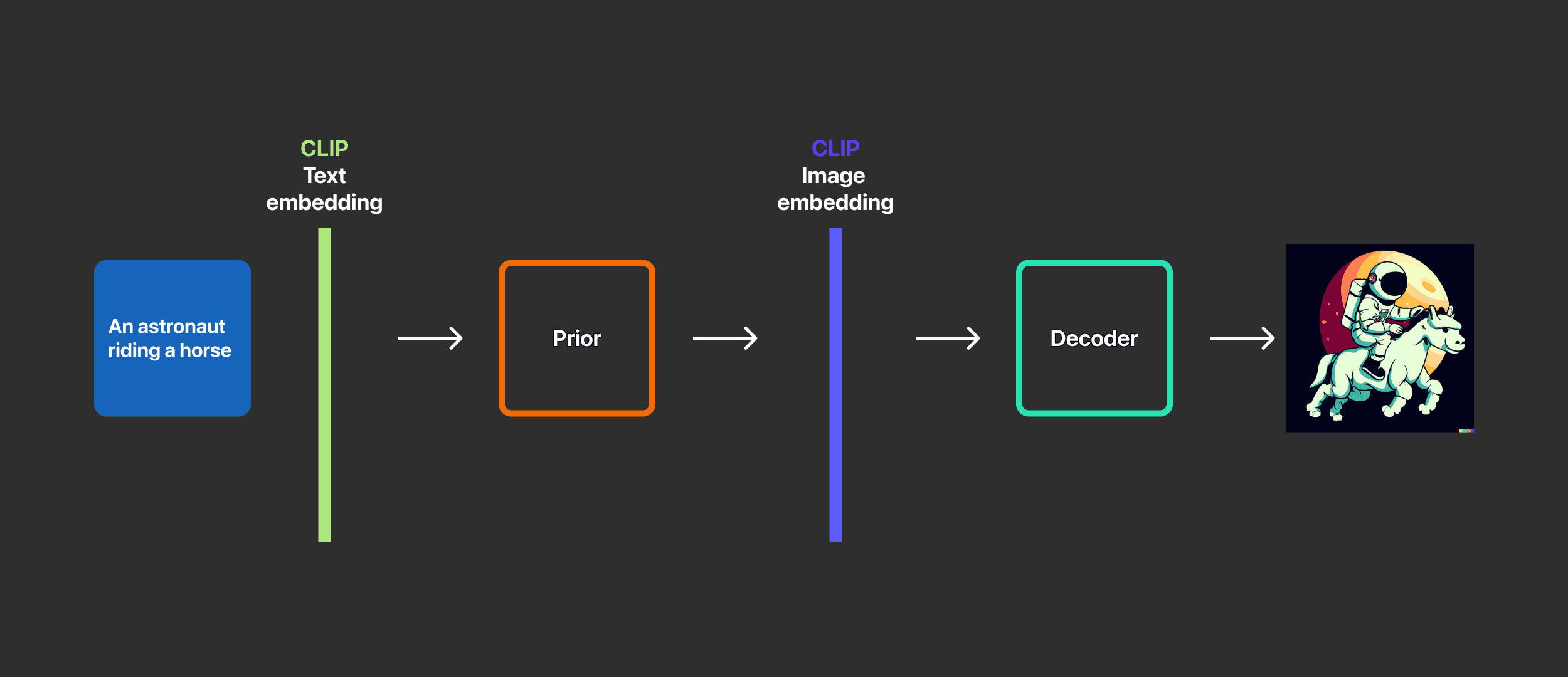
เบื้องหลังของ DALL·E 2 มีอยู่ด้วย 2 เทคโนโลยีคือ Clip และ Diffusion
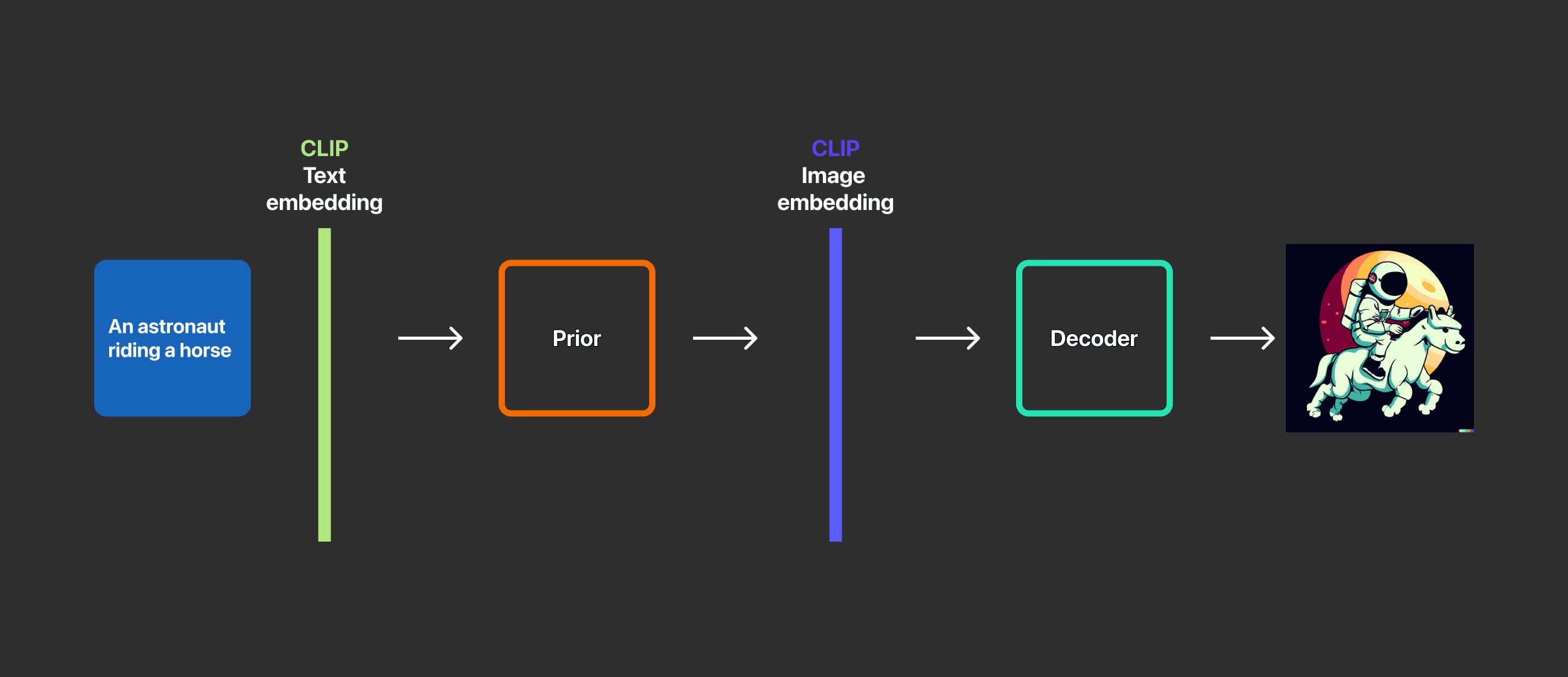 แผนภาพ Architecture ของ DALL·E 2
แผนภาพ Architecture ของ DALL·E 2
- Linking Textual and Visual Semantics
เริ่มแรกหลังจากป้อนข้อความเข้าไปจะมีการเชื่อมโยงความหมายข้อความ และรูปภาพ
ตัวอย่างคำบรรยายภาพ “An astronaut riding a horse in a photorealistic style”
แล้ว DALL·E 2 จะรู้ว่าแนวคิดของภาพนี้เป็นอย่างไรจึงมีเทคโนโลยีในการสร้างภาพจาก OpenAI ที่จะมาช่วยเทคโนโลยีนี้คือ Clip
Clip คือ Neural Network ที่จะส่งคืนคำอธิบายภาพที่ดีที่สุดเมื่อได้ภาพ โดยง่ายแบบเข้าใจคือ การจับคู่ภาพที่ตรงกับแนวคิด (Concept)
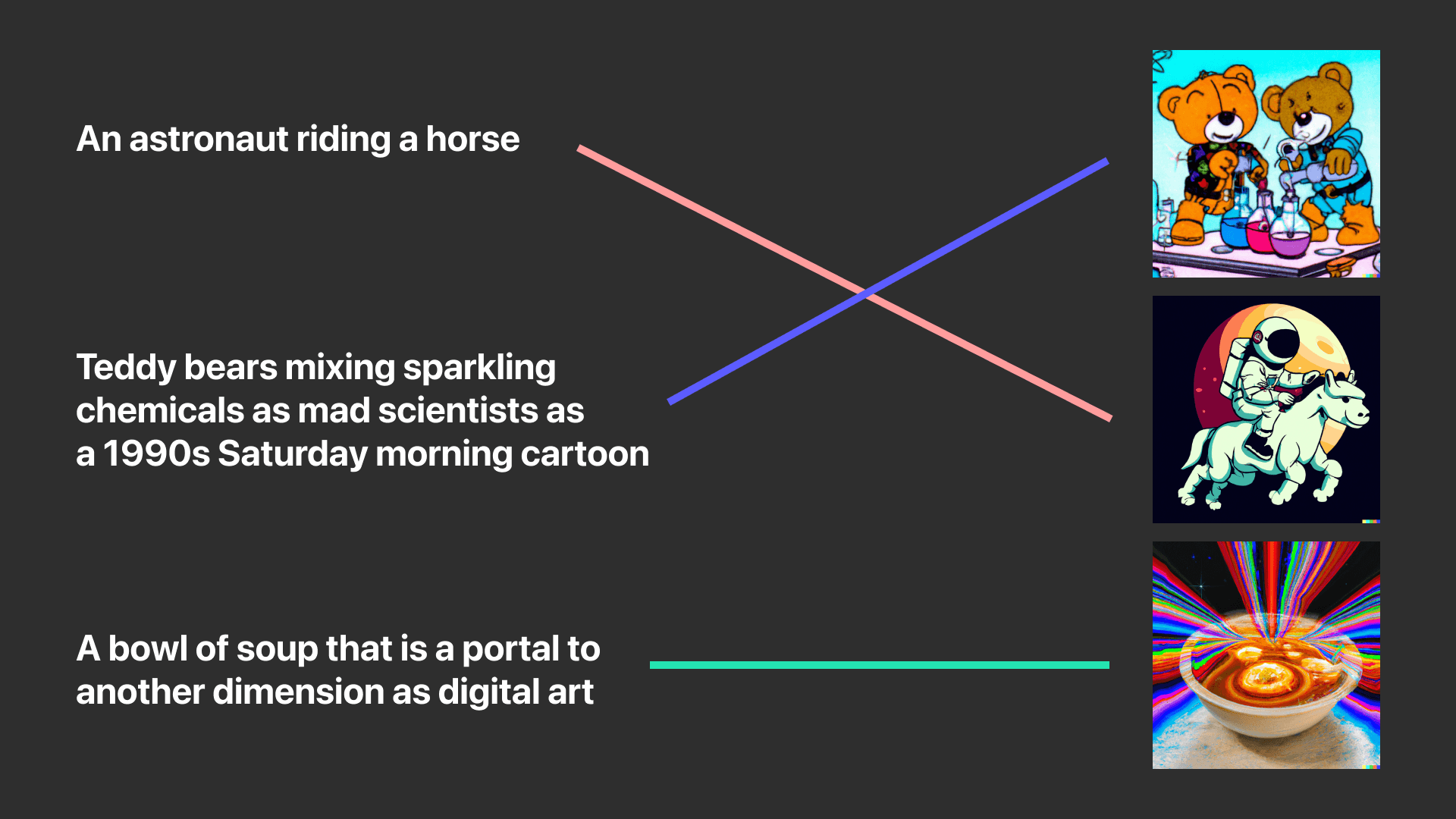 ตัวอย่างของการเชื่อมโยงความหมายของคำบรรยายภาพ และรูปภาพ
ตัวอย่างของการเชื่อมโยงความหมายของคำบรรยายภาพ และรูปภาพ
โดย Clip มี 2 Encoder (ตัวเข้ารหัส) ดังต่อไปนี้
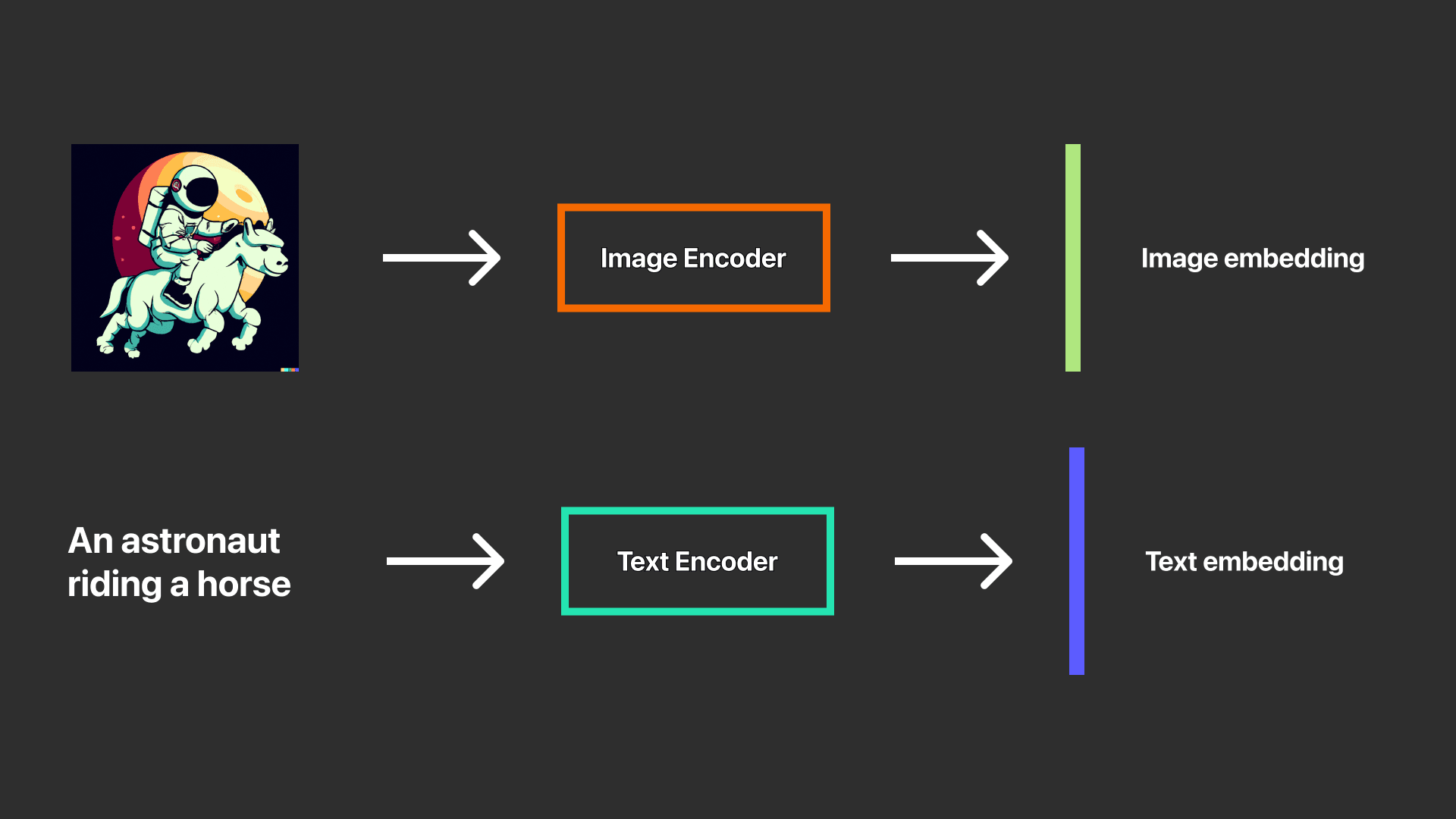 2 Encoder ของ Clip คือ Image Encoder และ Text Encoder
2 Encoder ของ Clip คือ Image Encoder และ Text Encoder
แปลงภาพผ่าน Image Encoder ไปเป็น Image embedding (ฝังรูปภาพ) และ แปลงข้อความผ่าน Text Encoder ไปเป็น Text embedding (ฝังข้อความ หรือ ฝังคำบรรยาย)
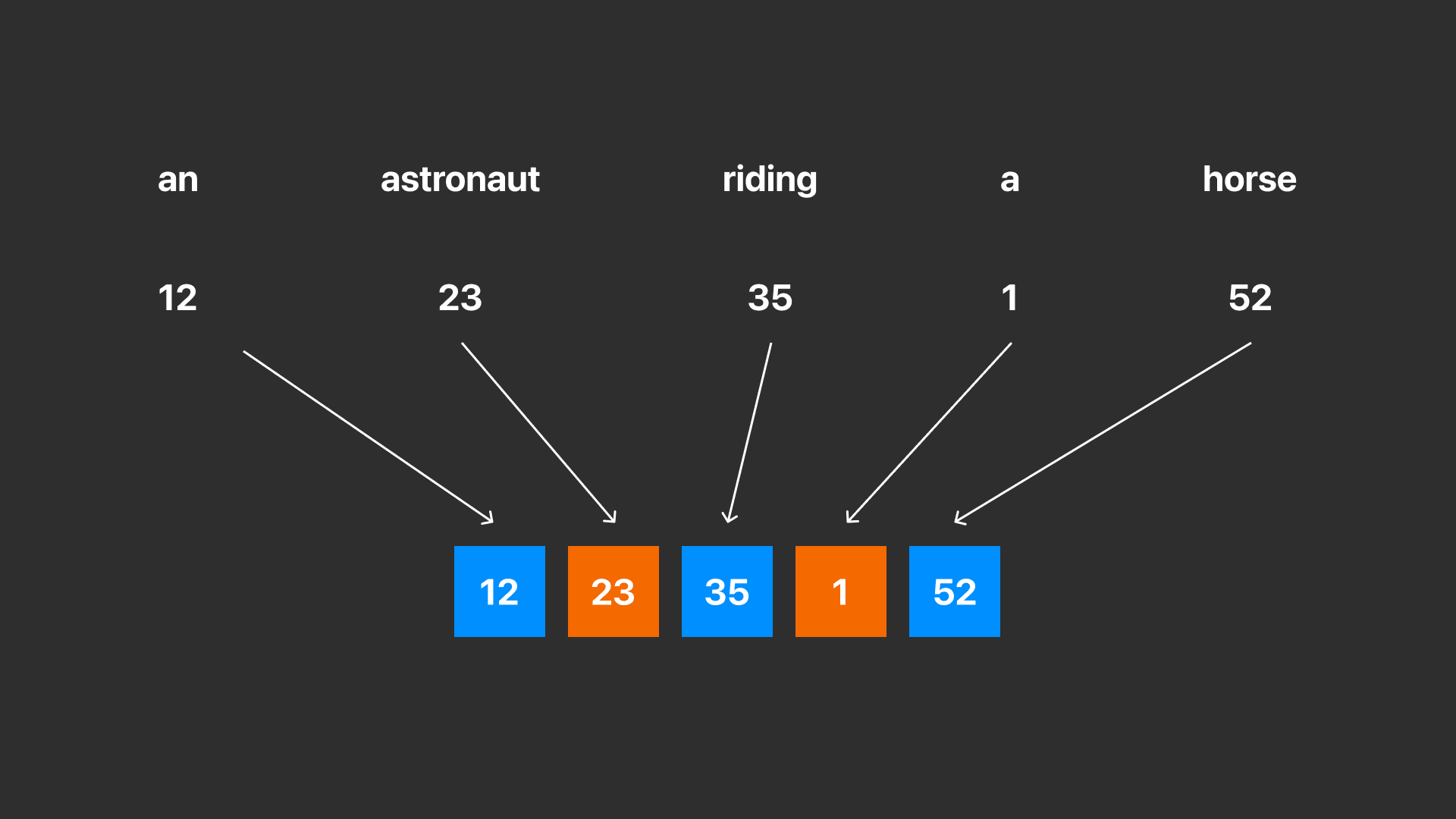 ตัวอย่าง การเปลี่ยนประโยคข้อความไปอยู่ในรูปเวกเตอร์
ตัวอย่าง การเปลี่ยนประโยคข้อความไปอยู่ในรูปเวกเตอร์
โดยทั้งสองวิธีเป็นวิธีทางคณิตศาสตร์ในการแสดงข้อมูล เช่น การเปลี่ยนประโยคข้อความไปอยู่ในรูปเวกเตอร์
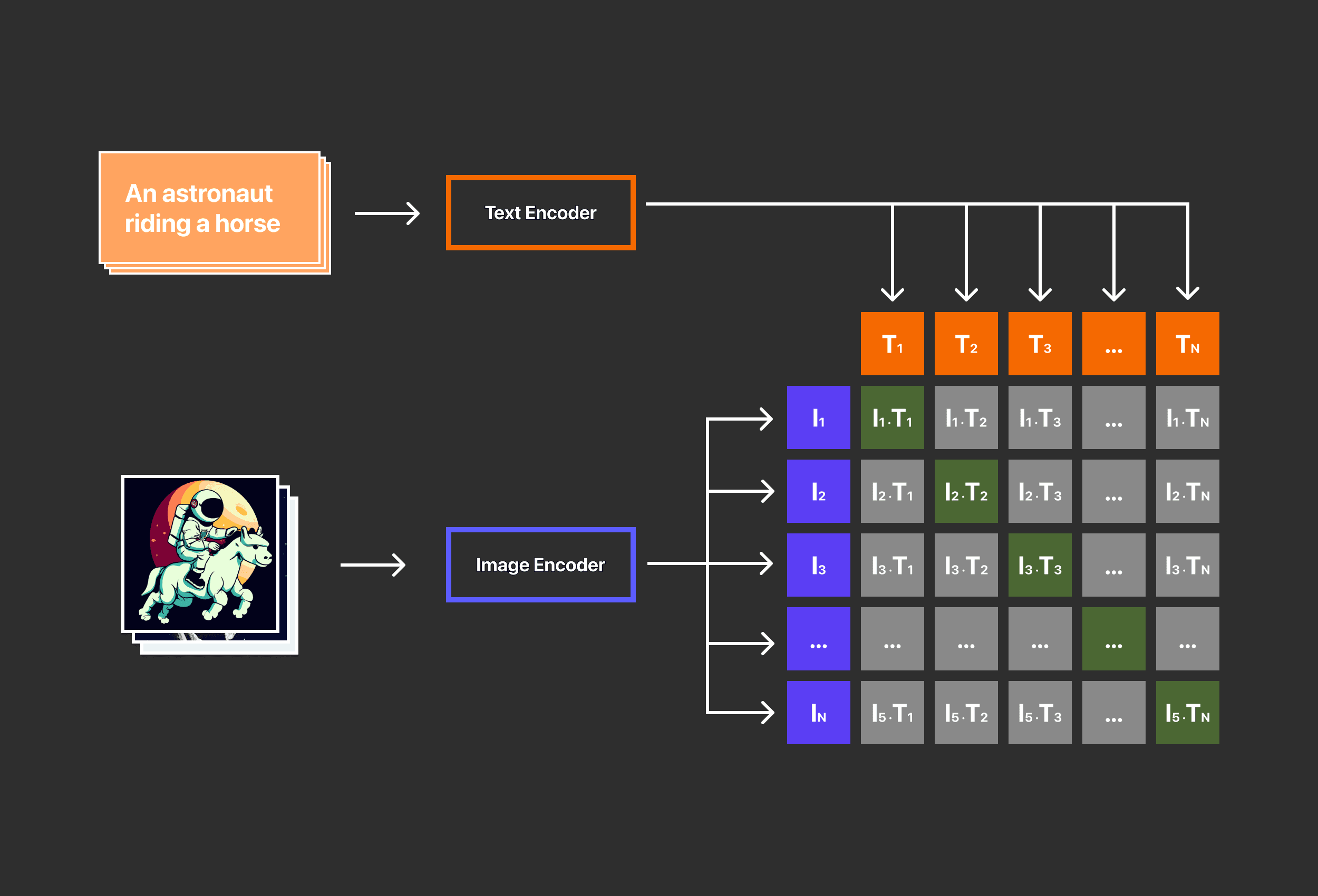 ภาพรวมของกระบวนการ CLIP Training Process
ภาพรวมของกระบวนการ CLIP Training Process
ค่าสีเทาคือค่าต่ำสุดในการจับคู่ระหว่าง Text embedding และ Image embedding
ค่าสีเขียวคือค่าสูงสุดในการจับคู่ระหว่าง Text embedding และ Image embedding
Clip จึงมีความสำคัญมากกับ DALL·E 2 เนื่องจากเป็นตัวกำหนดว่าข้อมูลโค้ดนั้นมีความเชื่อมโยงเกี่ยวข้องกับความหมายแนวคิดของภาพ หรือไม่ จึงสำคัญกับการสร้างภาพที่มีเงื่อนไข
- Connecting Textual Semantics to Corresponding Visual Semantics
หลังจากการทำงานฝึกโมเดลเสร็จ โมเดล Clip จะหยุดทำงานและ DALL·E 2 จะไปทำงานต่อเรื่องของการย้อนกลับการแมปเข้ากับรหัสภาพที่ Clip เรียนรู้ OpenAI จึงใช้เทคโนโลยีตัวนึงที่จะมาช่วยในการย้อนกลับคือ GLIDE โดยทาง OpenAI ได้มีการดัดแปลง GLIDE จากรุ่นก่อน ๆ เพื่อการสร้างรูปภาพ โมเดล GLIDE จะเรียนรู้กระบวนการกลับการเข้ารหัสรูปภาพเพื่อการถอดรหัสที่มีการฝังในรูปภาพที่โมเดล Clip ได้สุ่มไว้
เพื่อการสร้างภาพที่มีการรักษารายละเอียดดั้งเดิมรักษาลักษณะเด่นของรูปภาพการสร้างภาพ GLIDE จึงใช้โมเดลที่เรียกว่า Diffusion Model
Diffusion Model คืออะไร ?

แผนภาพ Diffusion Model [ภาพจาก Paper Denoising Diffusion Probabilistic Models]
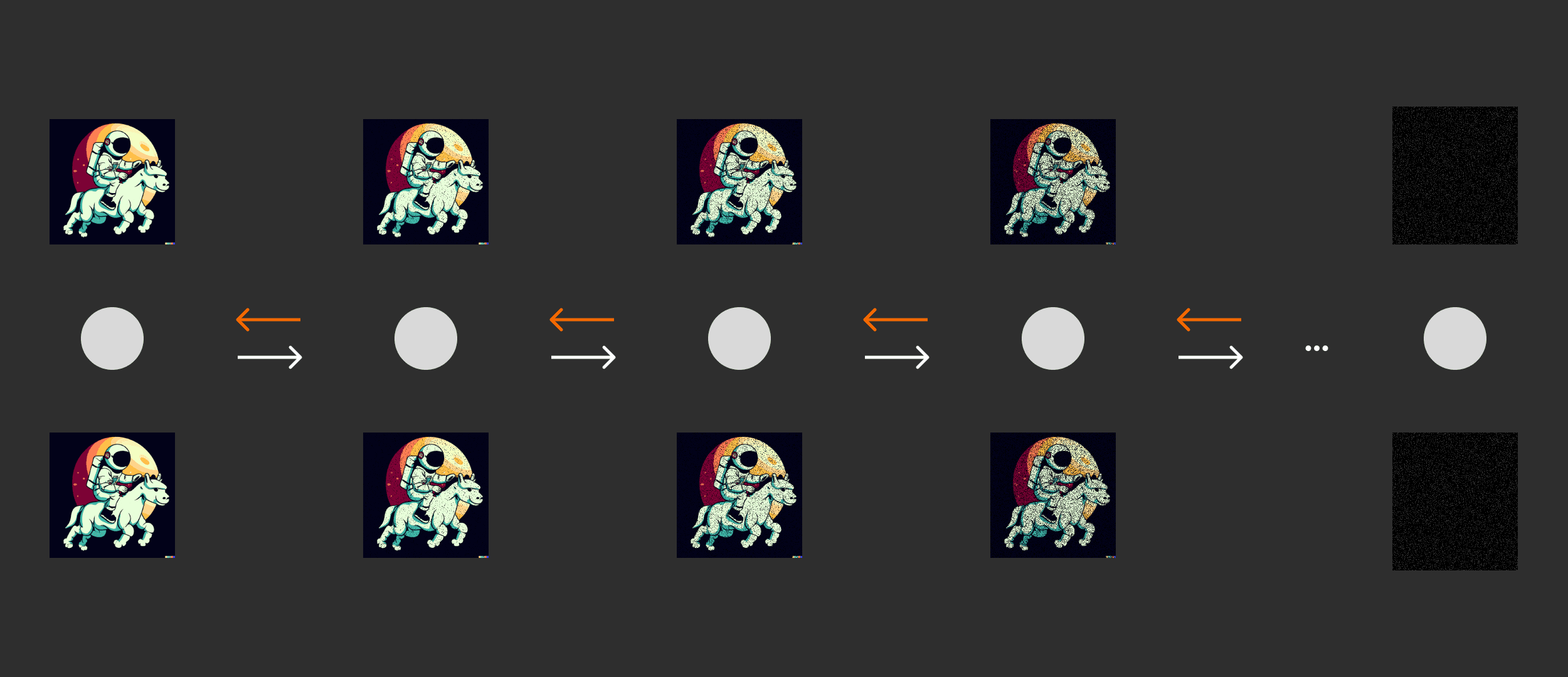 แผนภาพ Diffusion Model ที่มีการเทรนให้สร้างความเสียหายภาพด้วย Nosie และเรียนรู้การย้อนกลับการสร้างภาพใหม
แผนภาพ Diffusion Model ที่มีการเทรนให้สร้างความเสียหายภาพด้วย Nosie และเรียนรู้การย้อนกลับการสร้างภาพใหม
Diffusion Model คือแบบจำลองทำให้รูปภาพนั้นเกิดความเสียหายด้วยการเพิ่มสัญญาณรบกวน Noise จนไม่สามารถจำรูปภาพเดิมไม่ได้ และแบบจำลอง Diffusion Model ยังสามารถเรียนรู้การย้อนกลับเพื่อให้เรียนรู้การสร้างภาพขึ้นมาใหม่ให้อยู่ในสภาพเดิม การเรียนรู้นี้จะทำให้รู้วิธีการสร้างภาพ และข้อมูลอื่น ๆ ได้
ทำไม Prior Model จึงมีความสำคัญ
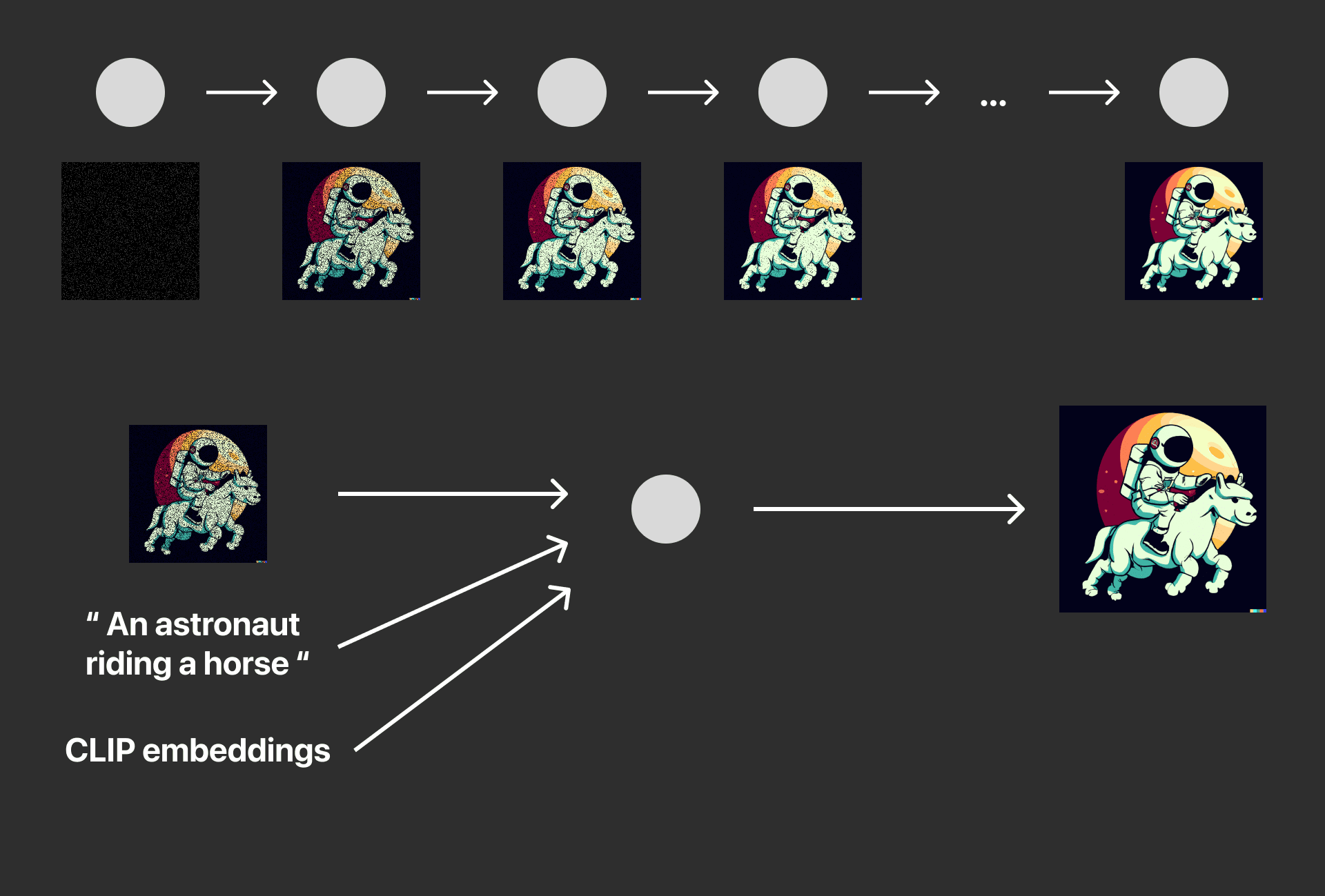
แล้วทำไมเราต้องเสียเวลาในขั้นตอนของ Prior ล่ะนักวิจัยก็ได้ทดลองว่าถ้าเราลองข้ามขั้นตอนบางอย่างจะเกิดผลอะไรบ้าง
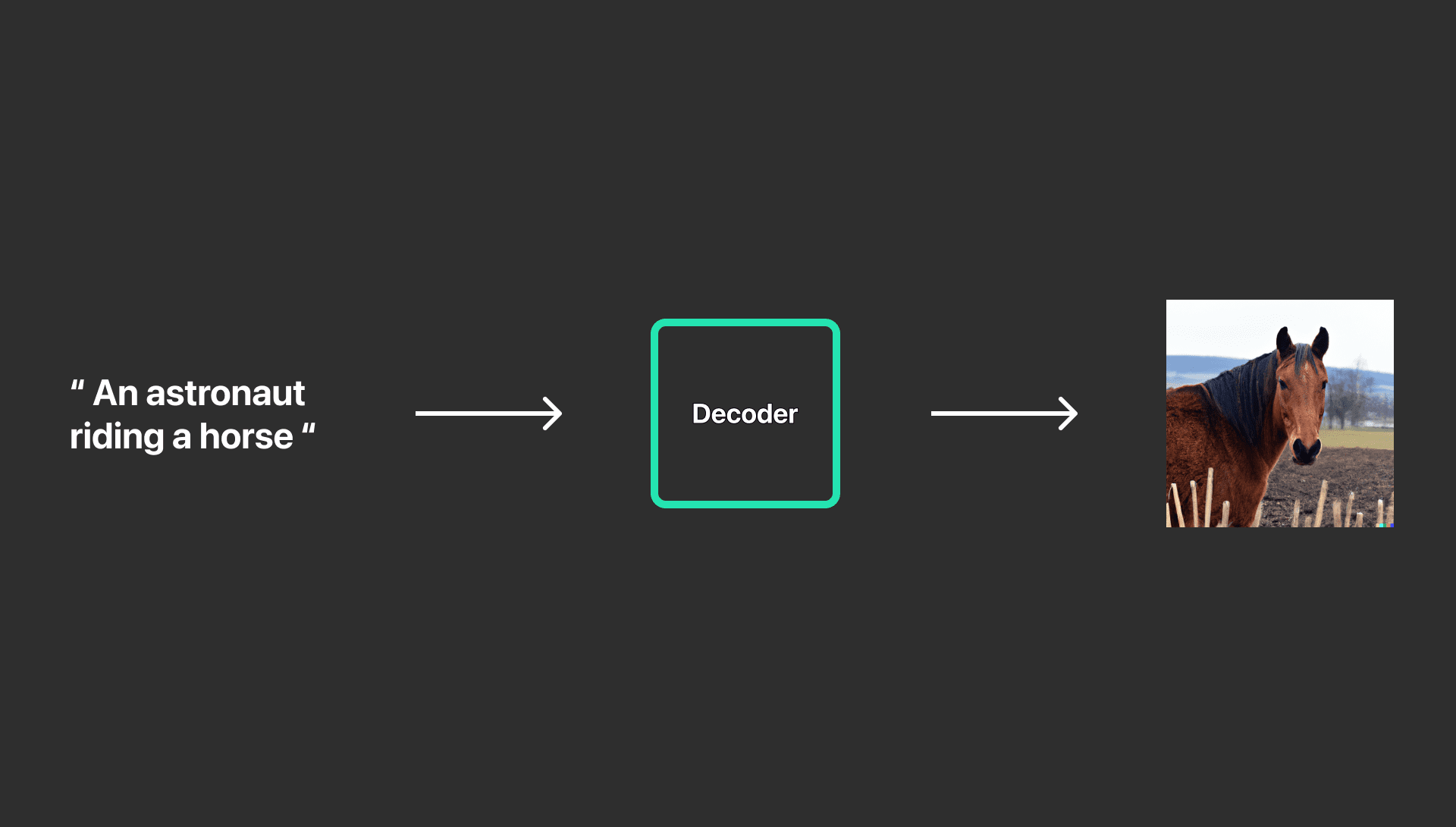 ข้อความผ่าน Decoder จะได้รูปภาพที่มีเพียง ม้า อย่างเดียว
ข้อความผ่าน Decoder จะได้รูปภาพที่มีเพียง ม้า อย่างเดียว
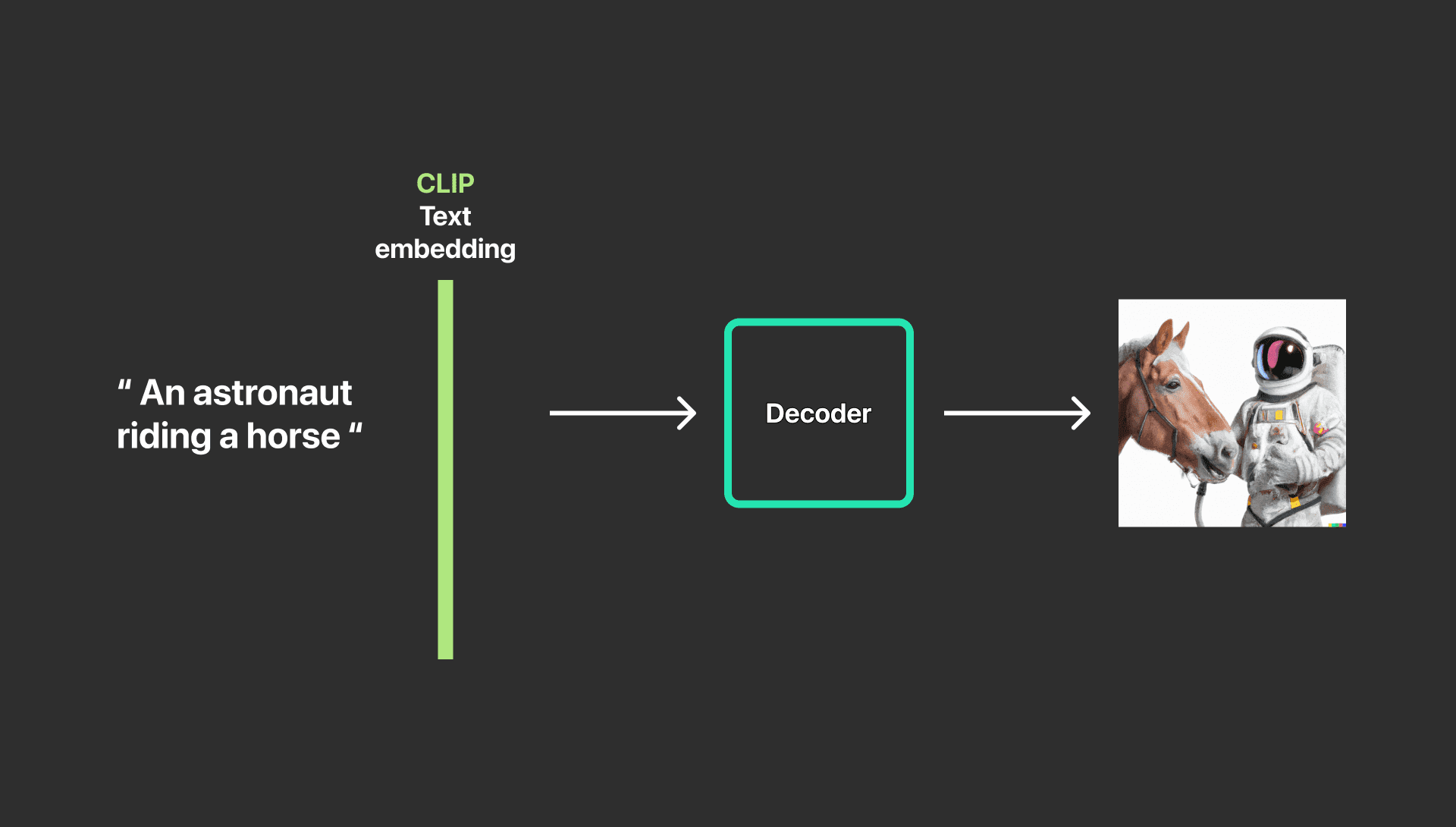 ข้อความผ่าน Clip Text Embedding และ Decoder จะได้รูปภาพที่มีเพียง ม้าและนักบินอวกาศ
ข้อความผ่าน Clip Text Embedding และ Decoder จะได้รูปภาพที่มีเพียง ม้าและนักบินอวกาศ
 รูปภาพผ่าน Prior generated image embedding จะให้ผลลัพธ์รูปภาพที่มีความสมบูรณ์
รูปภาพผ่าน Prior generated image embedding จะให้ผลลัพธ์รูปภาพที่มีความสมบูรณ์
ดังนั้น CLIP text embedding จึงมีความสำคัญสร้างผลลัพธ์ในทางที่ดี แต่การเอา CLIP text embedding ออกจาก DALL·E 2 จะสูญเสียความสามารถในการสร้างรูปแบบต่างของรูปภาพ
- Generating Image From Image Embeddings
 แผนภาพ GLIDE ที่มี Text Caption และ Clip Embedding
แผนภาพ GLIDE ที่มี Text Caption และ Clip Embedding
DALL·E 2 ใช้โมเดล GLIDE ที่ใช้แบบ Diffusion model ที่มีการดัดแปลงที่มีการรวม Text Information และ Clip Embedding เพื่อให้มีการรวบรวมข้อมูลที่หลากหลายอีกทั้งยังทำให้การสร้างรูปภาพตรงกับตามเงื่อนไขข้อความทีได้รับในตอนแรก
Upsampling
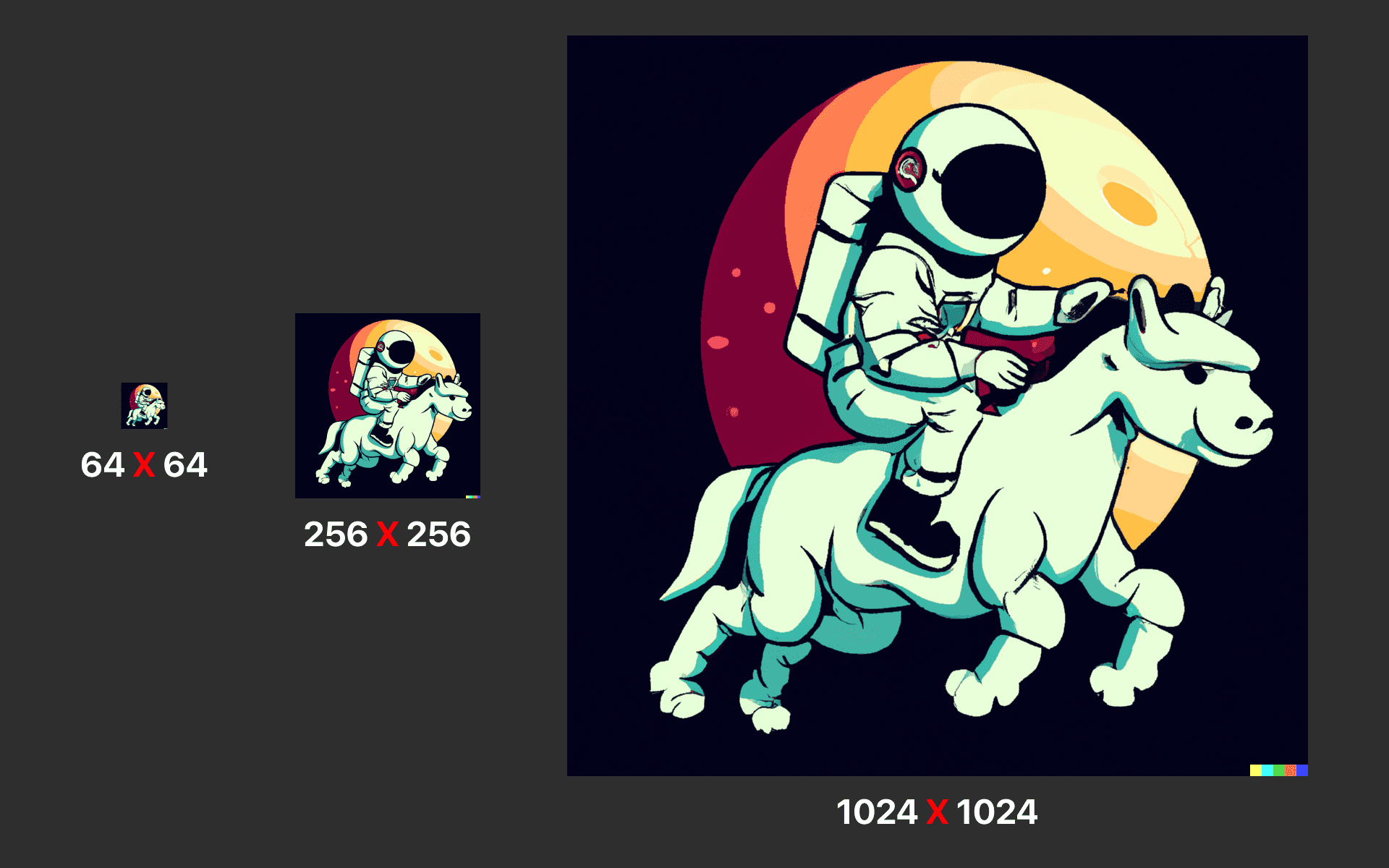 ตัวอย่างภาพของการ Upsampling DALL·E 2
ตัวอย่างภาพของการ Upsampling DALL·E 2
การสร้างรูปภาพเบื้องต้นจะเริ่มต้นจากขนาดความละเอียด 64 X 64 พิกเซล และจะมีการสุ่มตัวอย่างในการสร้างภาพที่มีขนาดความละเอียด 256 X 256 และ 1024 X 1024 พิกเซลตามมาเพื่อการสร้างภาพที่มีความละเอียดสูง
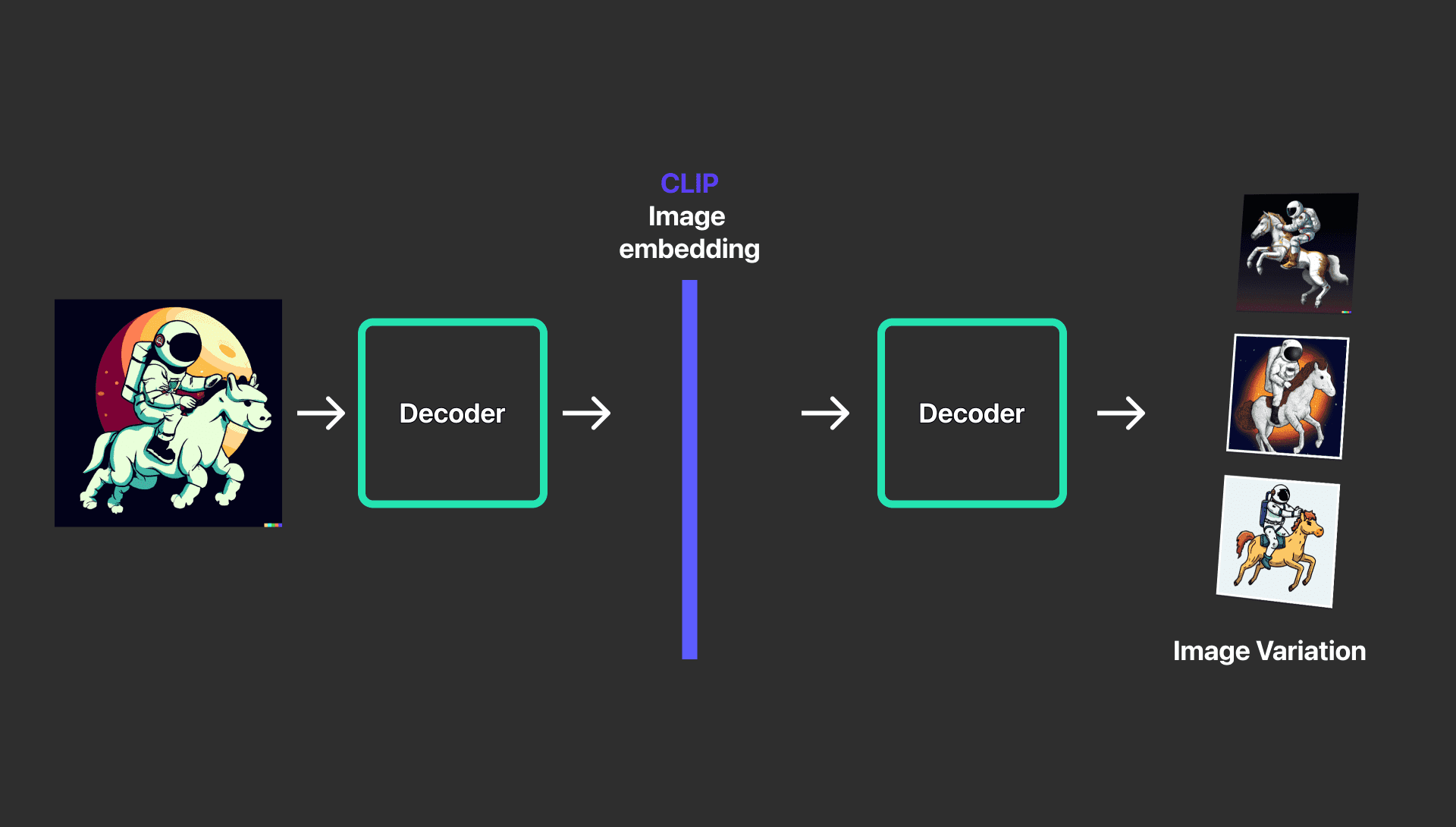
Variations แล้ว DALL·E 2 จะสร้างภาพที่มีความแตกต่างกันได้ยังไงเหรอ ?
การสร้างรูปแบบต่าง ๆ ของรูปภาพที่มีการกำหนดรายละเอียดที่ต้องการหมายความว่าคุณต้องการรักษาองค์ประกอบหลัก และสไตล์ของรูปภาพไว้ แต่มีการเปลี่ยนแปลงรายละเอียดเล็กน้อย
แต่ใน DALL·E 2 ซึ่งทำได้โดยการใช้ CLIP Image embedding และการเรียกใช้ Decoder โดยการใช้ตัวถอดรหัสด้วยหลักการ Diffusion Model โดยจะสร้างภาพที่มีหลายแบบและรักษารายละเอียดสำคัญต่าง ๆ
-
ข้อจำจัด ของ DALL·E 2 มีอะไรบ้างล่ะ ?
 “A sign that says deep learning” [ ภาพจาก Paper DALL·E 2 ]
“A sign that says deep learning” [ ภาพจาก Paper DALL·E 2 ]
ยังไม่สามารถสร้างภาพที่มีข้อความภายในภาพได้ดี เช่นให้สร้างป้ายประกาศข้อความ
 “a red cube on top of a blue cube” [ ภาพจาก Paper DALL·E 2 ]
“a red cube on top of a blue cube” [ ภาพจาก Paper DALL·E 2 ]
การเชื่อมโยงกับตำแหน่งของวัตถุยังไม่ดี เช่นให้สร้างภาพรูปที่มีลูกบาศก์สีน้ำเงินบนลูกบาศก์สีแดง โดยมักจะสับสนว่าลูกบาศก์สีไหนเป็นสีน้ำเงินหรือสีแดง
 “Times Square” [ภาพจาก Paper DALL·E 2]
“Times Square” [ภาพจาก Paper DALL·E 2]
การสร้างภาพที่มีฉากซับซ้อนยังไม่ค่อยดี เช่นการสร้างภาพของ Time Square ที่ให้ป้ายประกาศไม่มีข้อความ
ที่มา
https://www.assemblyai.com/blog/how-dall-e-2-actually-works/
https://medium.com/augmented-startups/how-does-dall-e-2-work-e6d492a2667f
https://www.blognone.com/node/127958
https://arxiv.org/pdf/2103.00020.pdf
https://arxiv.org/pdf/2102.12092v2.pdf
https://arxiv.org/pdf/2006.11239.pdf
https://arxiv.org/pdf/2112.10741.pdf
https://arxiv.org/pdf/2204.06125.pdf
หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้
-

-
-
ลดราคา!
-
ลดราคา!








