
 เขียนโดย
เขียนโดย
Sirasit Boonklang – BorntoDev Co., Ltd.

เขียนโดย
Sirasit Boonklang – BorntoDev Co., Ltd.
🔥 librosa คืออะไร ?!
Librosa เป็นแพ็คเกจ python ใช้สำหรับการวิเคราะห์เพลงและเสียง สามารถสร้างระบบดึงข้อมูลเพลงได้
💻 คำแนะนำในการติดตั้ง ?!
สามารถติดตั้งไลบรารี librosa ผ่านการใช้ Python Package Index (PyPI) ด้วยคำสั่งต่อไปนี้
pip install librosa หรือ sudo pip install librosa
🎼 แล้ว librosa ทำอะไรได้บ้างล่ะ ?!
สามารถดูตัวอย่างโค้ดจากผู้พัฒนา librosa ได้ที่ librosa/examples at main · librosa/librosa · GitHub
1. การโหลดอินพุตเสียง
นำเข้าไลบรารีที่เกี่ยวข้อง
#numpyสำหรับการดำเนินการทางคณิตศาสตร์ #matplotlib สำหรับแสดงผล #IPython.display สำหรับเอาต์พุตเสียง #Librosa สำหรับเสียง #โมดูลการแสดงผลสำหรับการแสดงภาพ import numpy as np import matplotlib.pyplot as plt %matplotlib inline import IPython.display import librosa import librosa.display
นำไฟล์เสียงที่ต้องการใช้งานอัปโหลดเข้ามาใน Google Colab การไปที่โฟลเดอร์ด้านซ้ายมือแล้วกดปุ่มอัพโหลด
จะเห็นได้ว่ามีไฟล์เสียง ที่เราได้ทำการอัพโหลดขึ้นมาเรียบร้อยแล้ว

เราจะใช้คำสั่ง librosa.load(‘ชื่อไฟล์เสียง’) ซึ่งจะได้ออกมา 2 ค่าคือ y1 และ sr1
y1 คือ ค่าความถี่เทียบกับเวลา
sr1 คือค่า sampling rate
sampling rate คือ อัตราการสุ่มตัวอย่างเสียงแอนาลอก เพื่อที่จะแปลงให้เป็นดิจิตอล
ตัวอย่าง y1, sr1 = librosa.load(‘borntodev.m4a’)
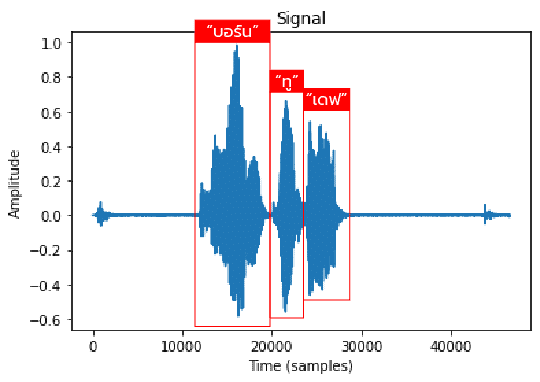
ทำการใช้คำสั่ง matlplotlib เพื่อแสดง waveform ของเสียงที่ใช้
plt.plot(y1); plt.title('Signal'); plt.xlabel('Time (samples)'); plt.ylabel('Amplitude');
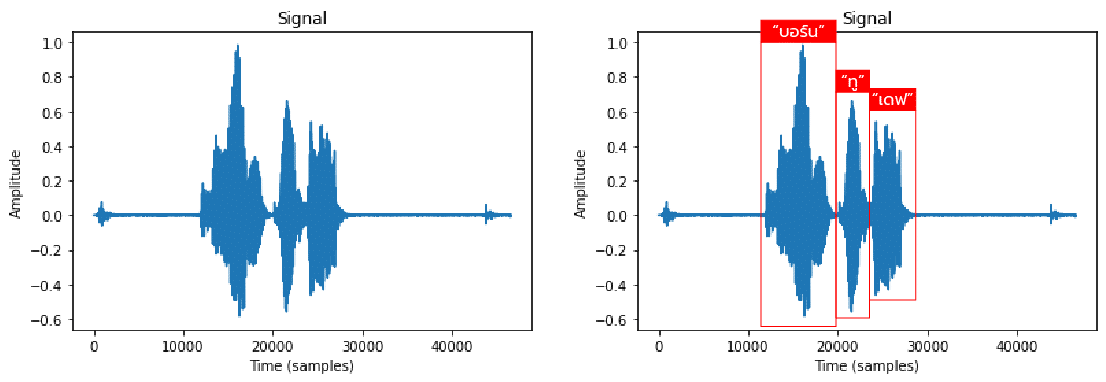
และเรายังสามารถนำตัวอย่างเสียงที่มีมากับไลบรารีมาใช้ในการวิเคราะห์เสียงได้ด้วยโดยใช้คำสั่ง librosa.util.example_audio_file() และแสดง Waveform ดังตัวอย่าง
audio_path = librosa.util.example_audio_file() y, sr = librosa.load(audio_path) plt.plot(y2); plt.title('Signal'); plt.xlabel('Time (samples)'); plt.ylabel('Amplitude');
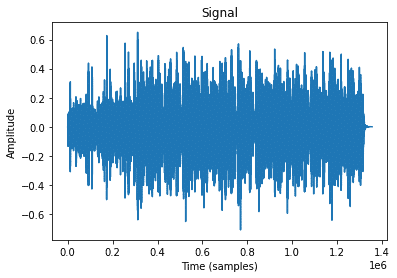
sampling rate ตามค่าเริ่มต้น librosa จะสุ่มสัญญาณใหม่เป็น 22050Hz
เราสามารถ แก้ไขค่า sampling rate ได้โดยการเพิ่มพารามิเตอร์ sr แล้วกำหนดค่าลงไปเช่น y, sr = librosa.load(audio_path, sr=44100) ค่า sr ก็จะเท่ากับ 44.1KHz
2. ใช้คำนวณ Mel spectrogram
เพื่อน ๆ สงสัยกันใช่มั้ยครับว่า Mel spectrogram คืออะไร เพื่อไม่ให้งง ก่อนอื่นเรามาทำความเข้าใจกับสัญญาณกันก่อนดีกว่าครับผม
สัญญาณ (Signal) เป็นการแปรผันของปริมาณหนึ่ง ๆ เมื่อเวลาผ่านไป
สัญญาณมีหลายแบบในที่นี้เราจะพูดถึง Continuous-time signal และ Discrete-time signal
Continuous-time signal คือ “ฟังก์ชันของตัวแปรเวลาต่อเนื่องที่มีชุดตัวเลขที่นับไม่ได้
ตัวอย่างสัญญาณเวลาต่อเนื่อง ได้แก่ คลื่นไซน์ คลื่นโคไซน์ คลื่นสามเหลี่ยม และอื่นๆ สัญญาณไฟฟ้ายังทำหน้าที่เป็นสัญญาณเวลาต่อเนื่องด้วย เมื่อสิ่งเหล่านี้ได้รับตามสัดส่วนกับพารามิเตอร์ทางกายภาพ เช่น ความดัน อุณหภูมิ เสียง และอื่นๆ
ในที่นี้เสียงต้นฉบับของเราเป็นสัญญาณแอนนาล็อกที่อยู่ในรูป Continuous-time signal
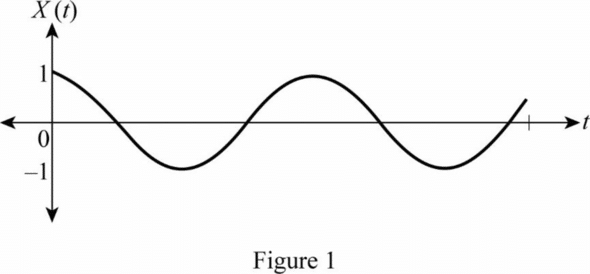 (ภาพจาก: Definition of Continuous And Discrete Signals | Chegg.com)
(ภาพจาก: Definition of Continuous And Discrete Signals | Chegg.com)
Discrete-time signal คือ สัญญาณตัวแปรที่มีชุดตัวเลขที่นับได้หรือจำกัดในลำดับของมัน” เป็นการแสดงสัญญาณเวลาต่อเนื่องแบบดิจิตอล
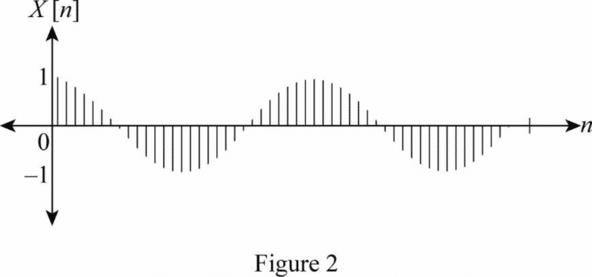 (ภาพจาก: Definition of Continuous And Discrete Signals | Chegg.com)
(ภาพจาก: Definition of Continuous And Discrete Signals | Chegg.com)
จากสัญญาณเสียงดนตรีที่เราได้ใช้ librosa โหลดมาแล้วแสดงเป็นกราฟของสัญญาณ
จะเห็นได้ว่าสัญญาณของเรามันอยู่ในโดเมนเวลา ซึ่งภาพในกราฟนี้เป็นการรวมกันของความถี่หลาย ๆ ความถี่ (เสียงจากเครื่องดนตรีต่าง ๆ รวมกันอยู่) แล้วต้องการแยกความถี่ของเสียงเครื่องดนตรีนั้น ๆ จะทำยังไงล่ะ สิ่งที่จะทำได้คือการแปลงสัญญาณจากโดเมนให้อยู่ในรูปของโดเมนความถี่โดยใช้ Fourier Transform
แล้วเจ้า Fourier Transform คืออะไรอีกล่ะ !?
Fourier Transform (FT) เป็นสูตรทางคณิตศาสตร์ที่ช่วยให้เราสามารถแยกสัญญาณออกเป็นความถี่เดี่ยวและแอมพลิจูดของความถี่ได้ กล่าวคือจะแปลงสัญญาณจากโดเมนเวลาเป็นโดเมนความถี่ ผลลัพธ์เรียกว่าสเปกตรัม
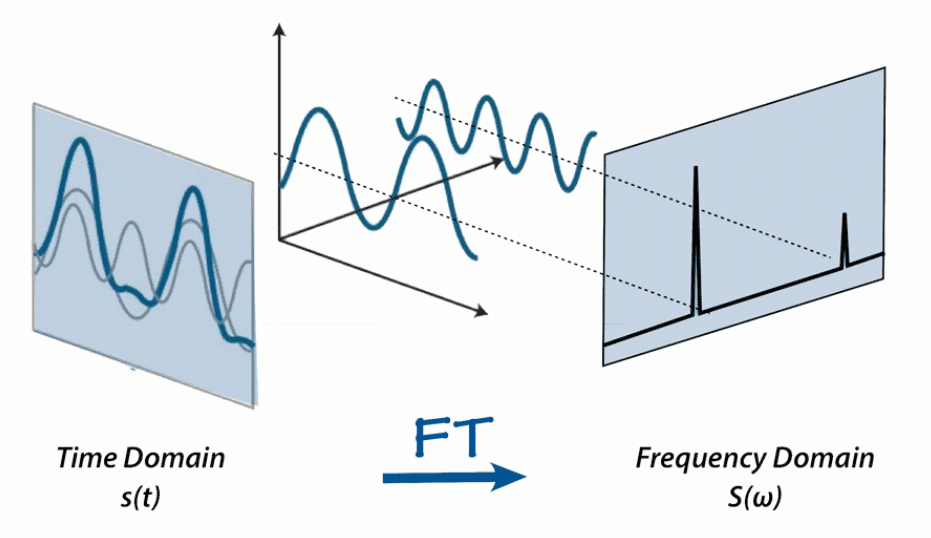 (ภาพจาก Fourier transform – AAVOS International)
(ภาพจาก Fourier transform – AAVOS International)
และยังมีอัลกอริทึมที่สามารถคำนวณการแปลงฟูริเยร์อย่างมีประสิทธิภาพ มีการใช้กันอย่างแพร่หลายในการประมวลผลสัญญาณ เรียกว่า Fast Fourier transform (FFT)
ซึ่งหากเราใช้ librosa เราก็จะไม่ต้องมาคำนวณแก้สมการเองเอง สามารถเรียกใช้งานได้เลย
n_fft = 2048 ft = np.abs(librosa.stft(y2[:n_fft], hop_length = n_fft+1)) plt.plot(ft); plt.title('Spectrum'); plt.xlabel('Frequency Bin'); plt.ylabel('Amplitude');
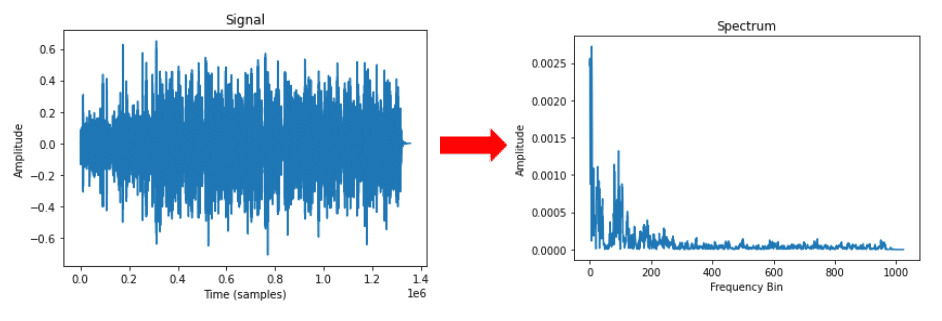 ใช้ fast Fourier transform (FFT) แปลงเป็น spectrum แล้วยังไงต่อล่ะ
ใช้ fast Fourier transform (FFT) แปลงเป็น spectrum แล้วยังไงต่อล่ะ
สเปกโตรแกรมเป็นกลุ่มของ FFT ที่ซ้อนกัน เป็นการแสดงความดังของสัญญาณหรือแอมพลิจูดของสัญญาณด้วยภาพ จะแตกต่างกันไปตามความถี่ที่ต่างกัน ตามเวลา เมื่อคำนวณสเปกโตรแกรม แกน y จะถูกแปลงเป็น log scale และ color dimension จะถูกแปลงเป็นเดซิเบล เนื่องจากมนุษย์สามารถรับรู้ช่วงความถี่และแอมพลิจูดที่มีขนาดเล็กและเข้มข้นเท่านั้น
แต่เอ๊ะ สงสัยมั้ยว่าเราจะดึงข้อมูลเสียงนี้มาทำให้ยุ่งเหยิงวุ่นวายทำไม เราได้ประโยชน์จากสิ่งนี้อย่างไร 🤔 มาหาคำตอบได้เลย
สเปกตรัมถูกนำมาใช้อย่างกว้างขวางในด้านดนตรี ภาษาศาสตร์ โซนาร์ เรดาร์ การประมวลผลเสียงพูด แผ่นดินไหววิทยา และอื่นๆ สเปกตรัมของเสียงสามารถใช้เพื่อระบุคำพูดตามสัทศาสตร์ และเพื่อวิเคราะห์เสียงเรียกต่างๆ ของสัตว์ได้ มาถึงตรงนี้เพื่อน ๆ น่าจะพอเข้าใจกันพอสมควรแล้วกับ “Spectrogram ” แต่เอ๊ะ แล้ว “Mel” ล่ะ คืออะไรกัน
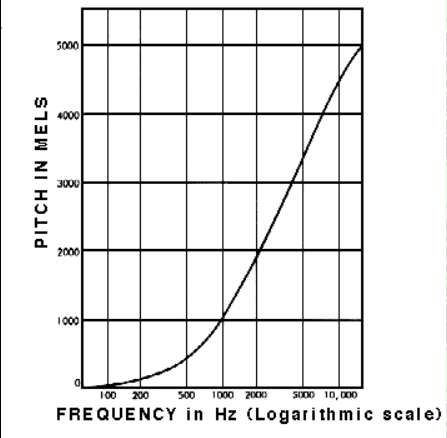
(ภาพจาก: https://www.sfu.ca/sonic-studio-webdav/handbook/Mel.html)
มนุษย์ไม่รับรู้ความถี่ในระดับเชิงเส้น เราสามารถบอกความแตกต่างของความถี่ที่ต่ำได้ดีกว่าความถี่ที่สูง ตัวอย่างเช่น เราสามารถบอกความแตกต่างระหว่าง 500 และ 1000 Hz ได้อย่างง่ายดาย แต่เราแทบจะไม่สามารถบอกความแตกต่างระหว่าง 10,000 ถึง 10,500 Hz ได้ แม้ว่าระยะห่างระหว่างสองคู่จะเท่ากัน
ในปี ค.ศ. 1937 Stevens, Volkmann และ Newmann ได้เสนอหน่วยของระดับเสียงที่ระยะห่างเท่ากันในระดับเสียงฟัง นี่เรียกว่ามาตราส่วนเมล หรือ Mel scale เราสามารถทำการคำนวณทางคณิตศาสตร์เกี่ยวกับความถี่เพื่อแปลงให้เป็น Mel scale ได้
ก็จะสรุปได้ว่า Mel Spectrogram ก็คือสเปกโตรแกรมที่ความถี่ถูกแปลงเป็นสเกลเมลนั้นเอง
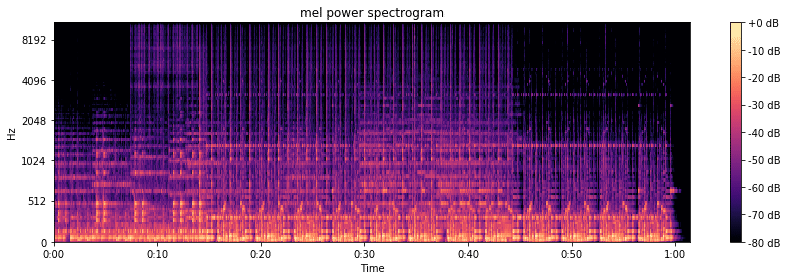
และเราสามารถใช้ librosa แสดงแผนภาพ heat map ของ Mel Spectrogram ได้ดังนี้
S = librosa.feature.melspectrogram(y2, sr=sr2, n_mels=128) log_S = librosa.power_to_db(S, ref=np.max) plt.figure(figsize=(12,4)) librosa.display.specshow(log_S, sr=sr2, x_axis='time', y_axis='mel') plt.title('mel power spectrogram') plt.colorbar(format='%+02.0f dB') plt.tight_layout()
3. ใช้คำนวณ Chromagram
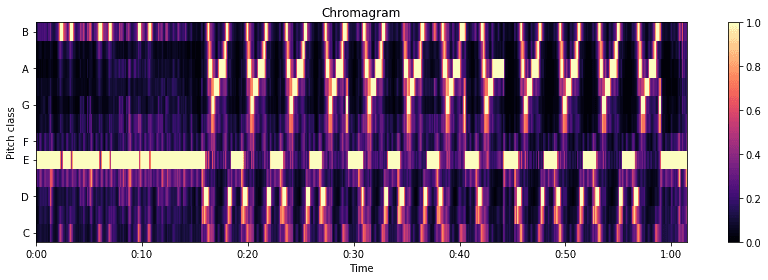
ในดนตรีตะวันตก chromagram มีความเกี่ยวข้องกับ pitch class 12 class ที่แตกต่างกัน คุณลักษณะที่อิงตาม Chroma ซึ่งเรียกอีกอย่างว่า “pitch class profiles” Pitch = ความถี่ของคลื่นเสียง Chromagram เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการวิเคราะห์เพลงซึ่งสามารถจัดหมวดหมู่ระดับเสียงที่มีความหมายได้ (มักเป็นสิบสองประเภท) และการปรับจูนนั้นใกล้เคียงกับระดับอารมณ์ที่เท่ากัน คุณสมบัติหลักประการหนึ่งของคุณสมบัติของโครมาคือคุณสมบัติเหล่านี้จับลักษณะฮาร์โมนิกและไพเราะของดนตรี ในขณะที่ยังคงแข็งแกร่งต่อการเปลี่ยนแปลงของเสียงต่ำและเครื่องมือวัด ซึ่งเราสามารถใช้ librosa แยกและแสดง Chromagram ของเสียงได้ดังนี้
C = librosa.feature.chroma_cqt(y=y_harmonic, sr=sr, bins_per_octave=36) plt.figure(figsize=(12,4)) librosa.display.specshow(C, sr=sr, x_axis='time', y_axis='chroma', vmin=0, vmax=1) plt.title('Chromagram') plt.colorbar() plt.tight_layout()
4. Beat tracking
เราสามารถทำตัวติดตามจังหวะ ซึ่งจะส่งกลับค่าประมาณของจังหวะ (เป็นครั้งต่อนาที) และดัชนีเฟรมของเหตุการณ์จังหวะ อินพุตสามารถเป็นอนุกรมเวลาของเสียง (ดังที่เราทำด้านบน) สามารถคำนวณโดย librosa.onset.onset_strength()
plt.figure(figsize=(12, 6)) tempo, beats = librosa.beat.beat_track(y=y_percussive, sr=sr) plt.figure(figsize=(12,4)) librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel') plt.vlines(librosa.frames_to_time(beats), 1, 0.5 * sr, colors='w', linestyles='-', linewidth=2, alpha=0.5) plt.axis('tight') plt.colorbar(format='%+02.0f dB') plt.tight_layout();
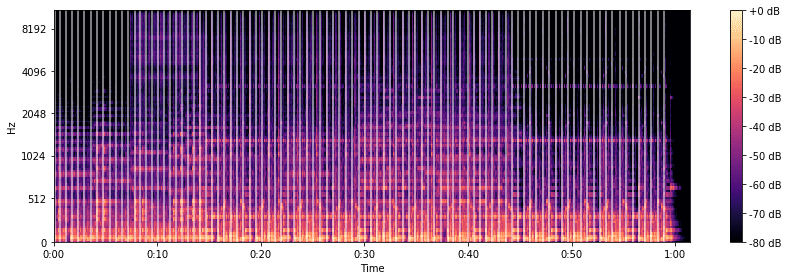
ตัวอย่าง การนำ Beat tracking ไปใช้ในเกม https://www.freecodecamp.org/news/use-python-to-detect-music-onsets/
นอกจากนั้นเรายังสามารถใช้ librosa ร่วมกับ Deep Learning ในการทำ Speech Recognition
เพื่อให้เราพูดกับคอมพิวเตอร์ได้อีกด้วยครับผม 😊 GitHub – jayeshsaita/Speech-Commands-Recognition: Speech Commands Recognition in PyTorch
**หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?**
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้




แนะนำสำหรับคุณ
สงวนลิขสิทธิ์ © 2565 - ข้อมูลและเนื้อหาทั้งหมด - บริษัท บอร์นทูเดฟ จำกัด


