

 โดย Chaiyaphop Jamjumrat (Bas)
โดย Chaiyaphop Jamjumrat (Bas)
Data Scientist at True Digital Group
“Stop doing Data Sciyasart! Please, Do Data Science!”
Intro to Data Science
ในช่วงต้นของศตวรรษที่ 21 Internet เริ่มถูกใช้งานกันอย่างแพร่หลายจนมาถึงทุกวันนี้ที่พวกเราทุกคนบนโลกแทบจะใช้งาน Internet กันตลอดเวลา เรียกได้ว่า 24/7 กันเลยทีเดียว ไม่ว่าจะเป็นการเล่น Social Media, ดู Streaming Service, เรียน Online, Shopping และอื่น ๆ อีกมากมาย ซึ่งมันทำให้ปริมาณของข้อมูลเพิ่มสูงขึ้นอย่างมหาศาลและไม่มีที่สิ้นสุด
ชนิดของข้อมูลก็มีความหลากหลายมากขึ้นเรื่อย ๆ ตามแหล่งที่มาของข้อมูลที่แตกต่างกันไป การสร้างและการเคลื่อนย้ายข้อมูลมีความเร็วมากขึ้นจากเทคโนโลยีต่าง ๆ ที่ถูกพัฒนาอยู่ตลอดเวลา ดังนั้นจากข้อมูลธรรมดาทั่ว ๆ ไปจึงกลายเป็น Big Data ที่เต็มไปด้วย Insights (ข้อมูลเชิงลึก) ที่มีประโยชน์ต่อธุรกิจในยุคปัจจุบัน และสามารถสร้างมูลค่าให้กับธุรกิจได้อย่างมหาศาล
นี่จึงเป็นเหตุผลที่ทำให้ข้อมูลมีมูลค่ามหาศาลตามไปด้วย อย่างที่ Clive Humby ได้เคยกล่าวไว้ว่า “Data is the new oil” คือข้อมูลเปรียบเหมือนกับน้ำมันของยุคปัจจุบันเลย และที่สำคัญ Big Data ยังเป็นแหล่งของข้อมูลจำนวนมหาศาลที่สามารถนำไปใช้ในการ Analytics (วิเคราะห์) และ Predictive Modeling (ทำนาย) ได้ และนี่จึงเป็นจุดเริ่มต้นของศาสตร์ที่มีชื่อว่า “Data Science” นั่นเอง
Data Science หรือ วิทยาการข้อมูล คืออะไร?
Data Science คือ ศาสตร์ในการวิเคราะห์ข้อมูลและอธิบายผลลัพธ์ของการวิเคราะห์ข้อมูลหรือถ้าจะอธิบายเป็น Process ในการทำงานของ Data Science ก็คือ กระบวนการที่ดึงเอาประโยนช์หรือ Insights ในข้อมูลออกมาอธิบายและสร้างมูลค่าให้กับธุรกิจ โดยจำเป็นต้องมี ทักษะ หรือ Skills ที่จะต้องใช้อยู่ 3 ด้านหลัก ๆ คือ
-
Hacking Skills คือ ทักษะทางด้านการเขียนโปรแกรม
-
Math & Statistics Knowledge คือ ความรู้ทางด้านคณิตศาสตร์และ สถิติ ซึ่งผมได้อธิบายความรู้พื้นฐานทางสถิติที่ Data Scientist ควรรู้ไว้ ที่นี่ https://web.facebook.com/borntodev/photos/a.830302417028053/5384984311559818/ แล้วนะครับ
-
Substantive Expertise คือ ความรู้เฉพาะทาง หรือความรู้ด้านธุรกิจ
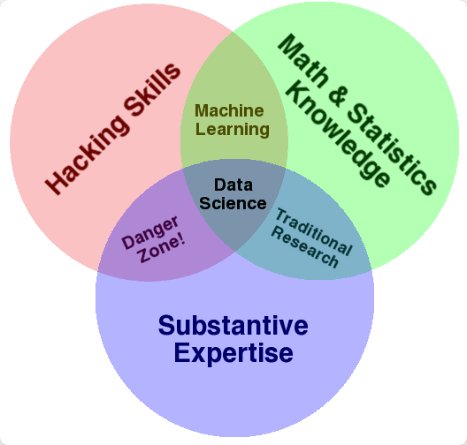
Image by THE DATA SCIENCE VENN DIAGRAM
ซึ่งคนที่จะต้องมี Skills ทั้งหมดก่อนหน้านี้ก็คือคนที่ทำงานสายตรงในศาสตร์ Data Science อย่าง “Data Scientist” นั่นเอง แล้วว่าแต่พวกเขาคือใคร ? ทำหน้าที่อะไร ? และทำไม Data Scientist จะต้องมี Skills ทั้งหมดก่อนหน้านี้ด้วย ? ไปทำความรู้จักกับเขากันครับ
Data Scientist หรือ นักวิทยาศาสตร์ข้อมูล คืออะไร?
Data Scientist คือ ตำแหน่งที่ต้องทำหน้าที่ศึกษาข้อมูลที่มีอยู่ให้เข้าใจอย่างถ่องแท้ เพื่อที่จะค้นหาหรือสามารถมองเห็นข้อมูล Insights ที่ซ่อนอยู่ในข้อมูลทั้งหมดได้ และนำมาวิเคราะห์ หรือ สร้างโมเดลทำนายอนาคต เพื่ออธิบายผลลัพธ์ที่ได้และเป็นแนวทางในการตัดสินใจให้กับธุรกิจ
Data Scientist ทำหน้าที่อะไรบ้าง?
Data Scientist ในแต่ละองค์กรจะมีหน้าที่ในการทำงานที่เฉพาะจงเจาะแตกต่างกันไปตามประเภทของธุรกิจหรือหน่วยงานนั้น ๆ บางที่ Data Scientist อาจจะต้องทำทุกอย่างใน Data Flow เลย หรือ บางที่ก็อาจจะทำแค่การวิเคราะห์ข้อมูล หรือ สร้างโมเดลทำนายอนาคตเฉย ๆ
ซึ่งจริง ๆ แล้ว Data Scientist ก็มีกระบวนการในการทำงานที่มีรูปแบบชัดเจนอยู่ และวันนี้เราจะมาแนะนำ Process ในการทำงานของ Data Scientist ที่ตัวผมเองเคยใช้ (SEMMA) และที่ Data Scientist เขานิยมใช้กัน คือ
-
SEMMA คือ กระบวนการมาตรฐานในการทำ Data Mining หรือ การทำเหมืองข้อมูล ของบริษัท SAS Institute หรือ เจ้าของโปรแกรม SAS ที่เรารู้จักกันนั่นเอง ซึ่ง SEMMA หมายถึงกระบวนการทำ Data Mining ที่แต่ละตัวอักษรหมายถึงการเรียงลำดับขั้นตอนในการทำ Data Mining โดยความหมายของแต่ละตัวอักษรก็คือ
-
-
S -> Sample คือ การสุ่มกลุ่มตัวอย่างจากกลุ่มเป้าหมายทั้งหมด และทำงานกับแค่ในกลุ่มตัวอย่างแทนที่จะทำงานกับกลุ่มเป้าหมายทั้งหมด เพื่อประหยัดต้นทุนแต่ยังคงประสิทธิภาพสูงสุดไว้เหมือนเดิม เช่น ถ้าเราสนใจที่จะศึกษาคนทั้งประเทศไทย เป็นไปได้ยากมากๆที่เราจะเก็บข้อมูลของคนทั้งประเทศได้หมด ดังนั้นเราจึงเก็บข้อมูลแค่ Sample หรือ กลุ่มตัวอย่าง ขึ้นมา และนำมาอธิบาย Population หรือ ประชากรทั้งหมดที่เราสนใจนั่นเอง Reference: https://web.facebook.com/borntodev/photos/a.830302417028053/5384984311559818/
-
-
-
E -> Explore คือ การสำรวจข้อมูลเพื่อหา Patterns และสิ่งผิดปกติในข้อมูล โดยการ Visualization หรือ ใช้เทคนิคทางสถิติ
-
M -> Modify คือ การปรับแต่งหรือแก้ไขข้อมูล โดยการสร้างตัวแปรใหม่ การเลือกตัวแปร ดัดแปลงตัวแปร และนำไปใช้ในโมเดล เพื่อเพิ่มประสิทธิภาพให้กับโมเดล
-
M -> Model คือ แบบจำลอง หรือ โมเดล ที่ถูกสร้างขึ่นมาเพื่อการคาดการณ์ผลลัพธ์ หรือทำนายอนาคต
-
A -> Assess คือ การประเมินผลลัพธ์ที่ได้จากโมเดลว่าผลลัพธ์มีประโยชน์แค่ไหน? และเชื่อถือได้หรือไม่? หรือเป็นการประเมินว่าโมเดลที่ถูกสร้างขึ่นมามีความแม่นยำเพียงใด?
-
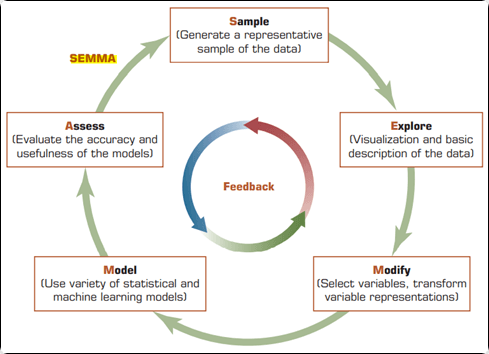
- Image by Data Mining SEMMA
2. CRISP-DM หรือ CRoss-Industry Standard Process for Data Mining คือ กระบวนการมาตรฐานในการวิเคราะห์ข้อมูล และทำ Data Mining ที่ถูกพัฒนาขึ้นในปี 1996 โดยความร่วมมือของ 3 บริษัท คือ DaimlerChrysler, SPSS และ NCR ซึ่งกระบวนการ CRISP-DM จะประกอบไปด้วย 6 ขั้นตอน คือ
-
-
Business Understanding คือ การเข้าใจปัญหา และแปลงปัญหาให้อยู่ในรูปของโจทย์สำหรับการวิเคราะห์ข้อมูล
-
Data Understanding คือ การเข้าใจข้อมูล เป็นการศึกษาข้อมูลที่มีอยู่ และตรวจสอบความถูกต้อง
-
Data Preparation คือ การเตรียมข้อมูลให้พร้อมสำหรับใช้งาน โดยมีการทำความสะอาดข้อมูล (Data Cleaning) และการดัดแปลงข้อมูล (Data Transformation) ให้สามารถนำไปวิเคราะห์ได้
เช่น การดัดแปลงข้อมูลให้อยู่ในช่วงที่กำหนด (Scale) และการเติมค่าให้ข้อมูลที่ขาดหายไป (Missing Values)
-
Modeling คือ การวิเคราะห์ข้อมูลโดยใช้เทคนิค Data Mining หรือ เทคนิค Machine Learning
-
Evaluation คือ การวัดประสิทธิภาพของโมเดลหรือผลลัพธ์ที่ได้ว่าตรงกับวัตถุประสงค์ที่ตั้งไว้หรือไม่ และเชื่อถือได้มากน้อยเพียงใด ซึ่งถ้าประสิทธิภาพของโมเดลหรือผลลัพธ์ที่ได้ ไม่เป็นไปตามที่คาดหวังไว้ สามารถย้อนกลับไปยังขั้นตอน Modeling อีกครั้งเพื่อปรับเปลี่ยนหรือแก้ไขให้ได้ผลลัพธ์ตามที่คาดหวังได้
-
Deployment คือ การอธิบายผลลัพธ์ที่ได้จากโมเดลให้กับธุรกิจ และการนำโมเดลหรือผลลัพธ์ที่ได้ไปใช้งานจริง
-
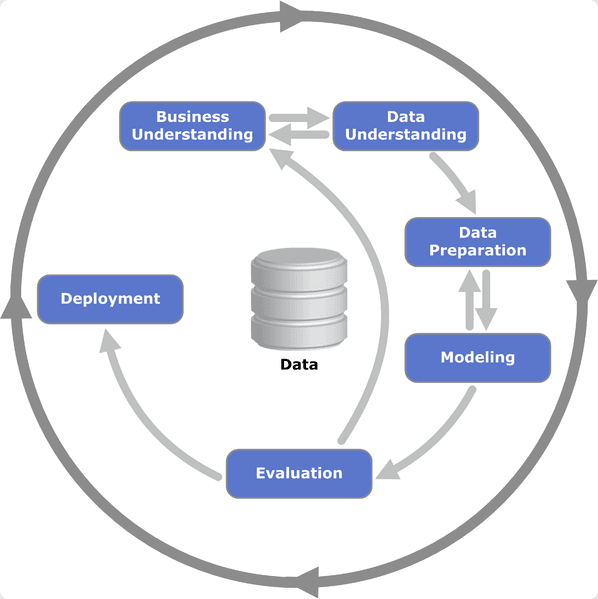 Image by CRISP-DM
Image by CRISP-DM
ถึง SEMMA และ CRISP-DM จะถูกคิดค้นมาเพื่อใช้ในการทำ Data Mining แต่ Data Mining ก็เป็นศาสตร์ที่มีความคล้ายคลึงกับ Data Science ในหลาย ๆ ด้านเลย ดังนั้น Data Scientist จึงนิยมนำเอาทั้ง SEMMA และ CRISP-DM มาประยุกต์ปรับใช้ในงาน Data Science
3. OSEMN คือ 5 ขั้นตอนสำหรับการทำ Data Science
-
-
O -> Obtain คือ การเก็บรวบรวมข้อมูล
-
S -> Scrub คือ การทำความสะอาดข้อมูล (Data Cleaning)
-
E -> Explore คือ การสำรวจข้อมูล และศึกษาทำความเข้าใจกับข้อมูล โดยสามารถใช้การทำ Data Visualization ในการศึกษาข้อมูลได้
-
M -> Model คือ การสร้างแบบจำลองหรือโมเดล เพื่อทำนายผล (Predictive Model)
-
N -> Interpret คือ การนำเสนอและอธิบายผลลัพธ์ที่ได้จากโมเดลให้กับธุรกิจ
-
จากทั้ง 3 กระบวนการสำหรับการทำ Data Science ข้างต้นนั้น จะเห็นได้ว่าทั้ง 3 กระบวนการมีความคล้ายคลึงกันทั้งหมดเลย อาจจะแตกต่างกันไปตามลักษณะของการใช้งาน เราจึงนำมาสรุปเป็นขั้นตอนหลัก ๆ ในการทำ Data Science ได้ 4 ขั้นตอน คือ
-
-
การเก็บรวบรวมข้อมูล
-
การจัดการข้อมูล
-
การวิเคราะห์ข้อมูล
-
การนำไปใช้จริง
-
ระยะเวลาส่วนใหญ่ในการทำ Data Science ของ Data Scientist นั้น มักจะถูกใช้ไปกับขั้นตอนการจัดการข้อมูล หรือขั้นตอนการศึกษาข้อมูล เนื่องจากเป็นขั้นตอนที่ค่อนข้างมีความซับซ้อน ยุ่งยาก และยังต้องใช้เวลาอย่างมากในการทำความเข้าใจข้อมูลอีกด้วย
สรุป
Big Data เป็นหนึ่งในเหตุผลหลัก ๆ ที่สำคัญที่ทำให้เกิดศาสตร์ Data Science และอาชีพ Data Scientist ขึ้นมา เพื่อมาจัดการ และวิเคราะห์หาผลประโยชน์จาก Big Data โดยใช้ทักษะทางคณิตศาสตร์และสถิติ โปรแกรมมิ่ง และความรู้ด้านธุรกิจ มารวม ๆ กันนั่นเอง
อ้างอิงจาก
- Data Mining SEMMA, สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://sis.binus.ac.id/2021/09/30/data-mining-semma/
- What is SEMMA?, สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://www.datascience-pm.com/semma/
- SEMMA, สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://en.wikipedia.org/wiki/SEMMA
- What is CRISP DM? สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://www.datascience-pm.com/crisp-dm-2/#:~:text=Compared%20to%20CRISP%2DDM%2C%20SEMMA,cover%20the%20final%20Deployment%20aspects
- Cross-industry standard process for data mining, สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
- A Beginner’s Guide to the Data Science Pipeline, สืบค้นเมื่อ 29 ก.ค. 2565 จาก: https://towardsdatascience.com/a-beginners-guide-to-the-data-science-pipeline-a4904b2d8ad3
หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้
-

-
Sale!
-
Sale!
-
Sale!








