ตัวอย่างการใช้ประโยชน์ Web Scraping ได้แก่:
- การดึงข้อมูลราคาสินค้าจากเว็บไซต์อีคอมเมิร์ซเช่น amazon, ebay หรือ alibaba
- ดึงโพสต์ ไลค์ คอมเมนต์ ผู้ติดตาม จากโซเชียลมีเดีย
- ดึงข้อมูลผู้ติดต่อจากเว็บไซต์ต่าง ๆ เช่น Linkedin
ซึ่ง Web Scraping สามารถใช้เครื่องมือหรือภาษาที่หลากหลายในการทำ Web Scraping ได้
โดยวันนี้เราจะมาใช้ Puppeteer ซึ่งเป็นไลบรารี่สำหรับการทำ Web Scraping ใน Node.JS กัน
Puppeteer คืออะไร
Puppeteer เป็น Node ไลบรารี ที่มี API ระดับสูงเพื่อควบคุม Chrome หรือ Chromium ผ่านโปรโตคอล DevTools และ Puppeteer ทำงานแบบ headless แต่สามารถกำหนดค่าให้เรียกใช้ Chrome หรือ Chromium แบบเต็มได้
Headless Chrome คือ วิธีการเรียกใช้เบราว์เซอร์ Chrome ในสภาพแวดล้อมที่ไม่มีส่วนหัว คือการใช้งาน Chrome โดยไม่ต้องใช้ Chrome! จะเป็นการนำคุณลักษณะแพลตฟอร์มเว็บที่ทันสมัยทั้งหมดที่มีให้โดย Chromium และเอ็นจิ้นการเรนเดอร์ Blink ไปยัง command line
ฟีเจอร์เด่น ๆ ของ Puppeteer ได้แก่
- ความสามารถในการแยกเนื้อหาข้อความขององค์ประกอบที่คัดลอกมา
- ความสามารถในการโต้ตอบกับหน้าเว็บโดยการกรอกแบบฟอร์ม
- ความสามารถในการทำ Web Scraping และดาวน์โหลดรูปภาพจากเว็บ
สามารถอ่านเพิ่มเติมเกี่ยวกับ Puppeteer ได้ที่ puppeteer/puppeteer: Headless Chrome Node.js API (github.com)
มาเริ่มทำ Web Scraping ด้วย Node.JS กันเลย
1.หากยังไม่มี Node.JS ให้ทำการโหลด Node.JS ก่อนได้ที่ Download | Node.js (nodejs.org)
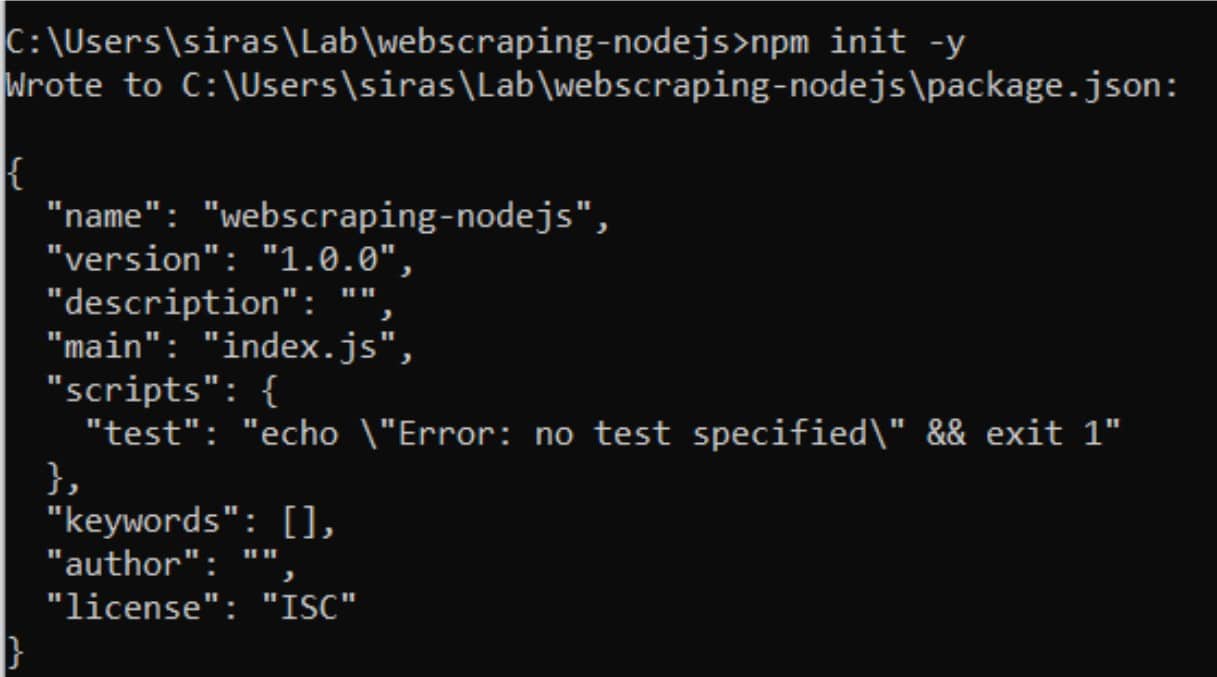
2.สร้างไฟล์ package.json ด้วยคำสั่ง npm init -y
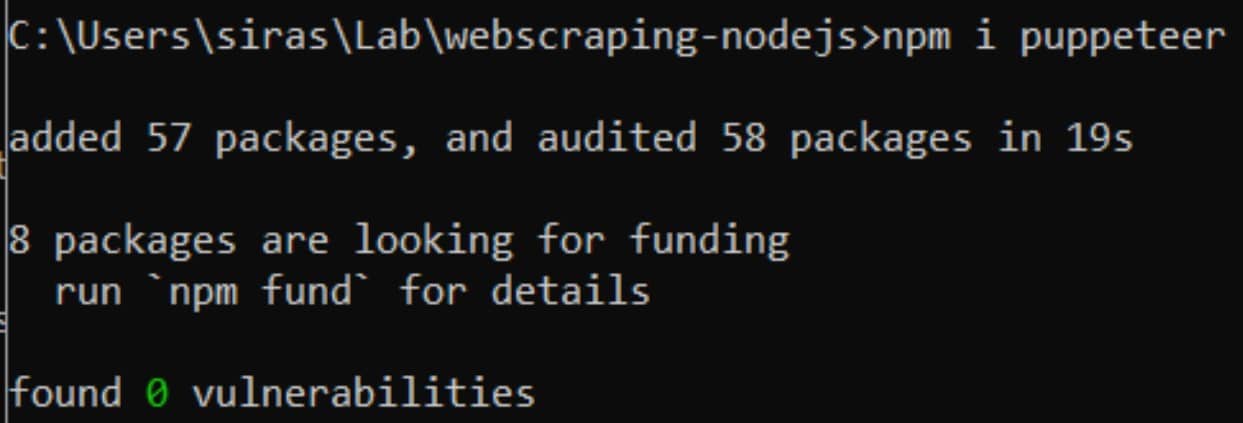
3.ทำการติดตั้ง puppeteer ด้วยคำสั่ง npm i puppeteer
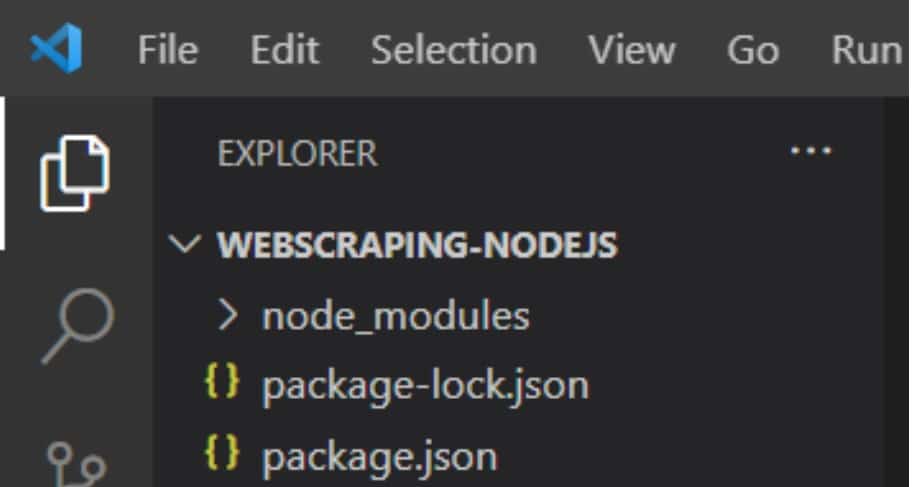
4.เมื่อติดตั้ง puppeteer แล้ว และใช้คำสั่ง code .เพื่อเปิด Visual Studio Code จะพบ node_modules ขึ้นมา
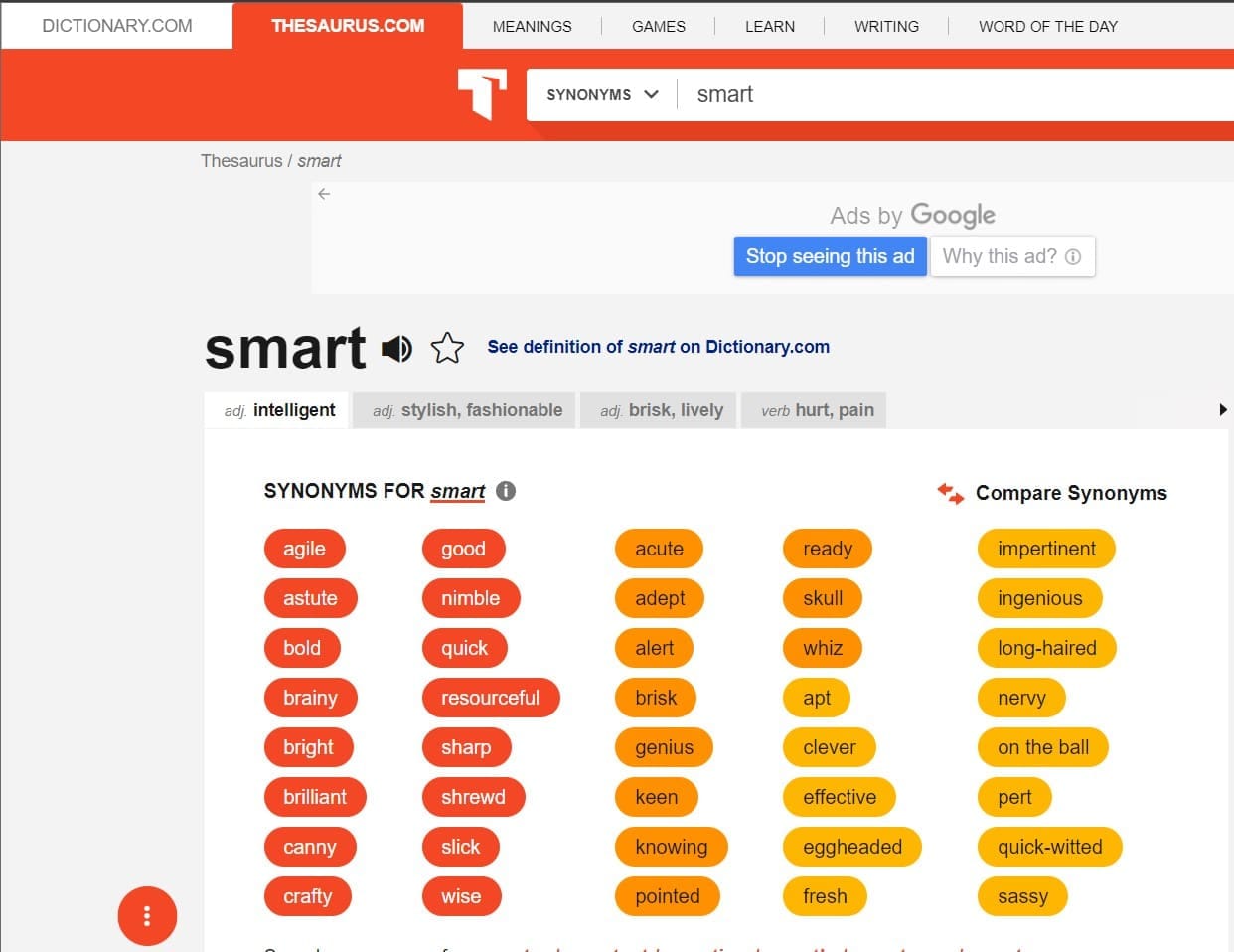
5.โดยตัวอย่างนี้เราจะทำการดึงคำพ้องความหมายของคำว่า “smart” จากเว็บ https://www.thesaurus.com/browse/smart
6.จากนั้นไปที่ Visual Studio Code แล้ว สร้างไฟล์ JavaScript โดยตัวอย่างนี้จะตั้งชื่อว่า “index.js” หรือสามารถตั้งชื่ออะไรก็ได้ตามต้องการ แต่จะต้องใช้ require(‘puppeteer’) ในบรรทัดแรกและสร้างฟังก์ชัน async ซึ่งเราจะเขียนโค้ดดังนี้
const puppeteer = require('puppeteer')
async function scrape() {
}
scrape()
7.ขั้นต่อไปให้เริ่มต้นอินสแตนซ์ของเบราว์เซอร์ใหม่และกำหนดตัวแปร “page” ซึ่งใช้สำหรับไปยังหน้าเว็บและคัดลอกองค์ประกอบภายในเนื้อหา HTML ของหน้าเว็บ
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
}
scrape()
8.หากต้องการค้นหาและคัดลอกคำพ้องความหมายของ “smart” ตัวแรก ก่อนอื่นให้ไปที่คำพ้องความหมายของ “smart” คลิกที่คำพ้องความหมายแรกและคลิกที่ “inspect” ซึ่งจะทำให้ DOM ของหน้าเว็บนี้ปรากฏขึ้นที่ด้านขวาของหน้าจอ
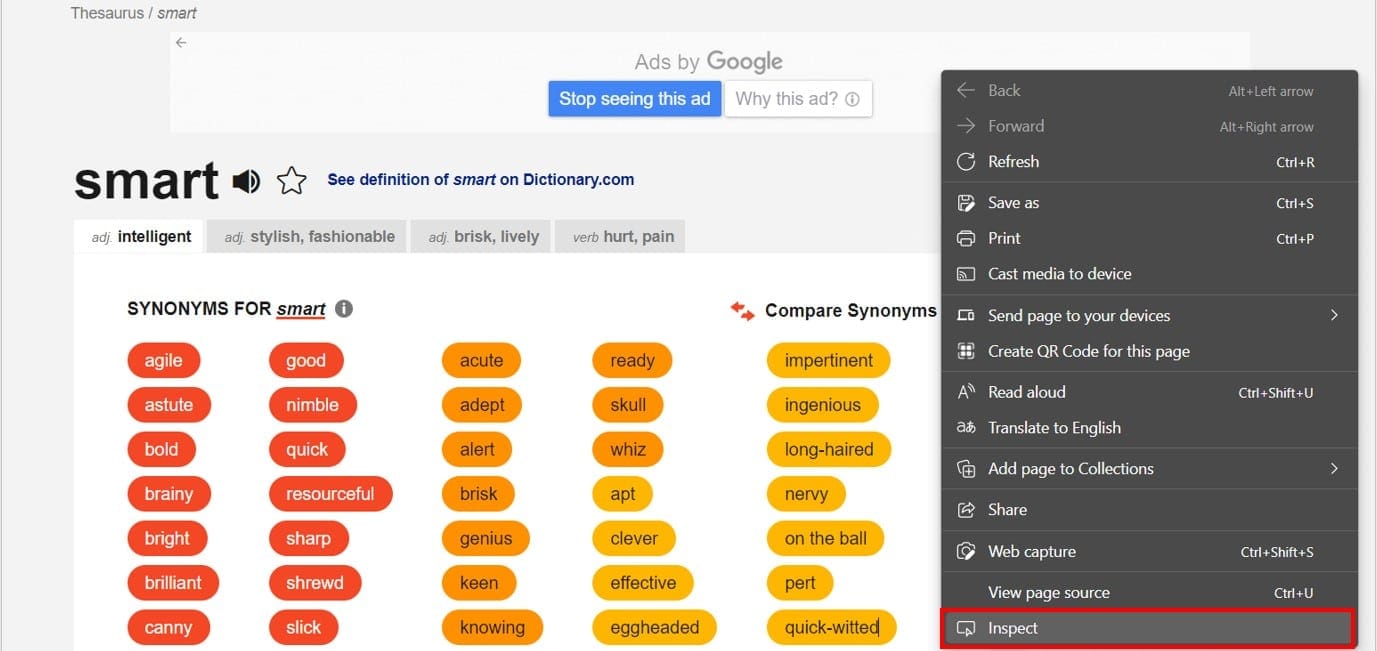
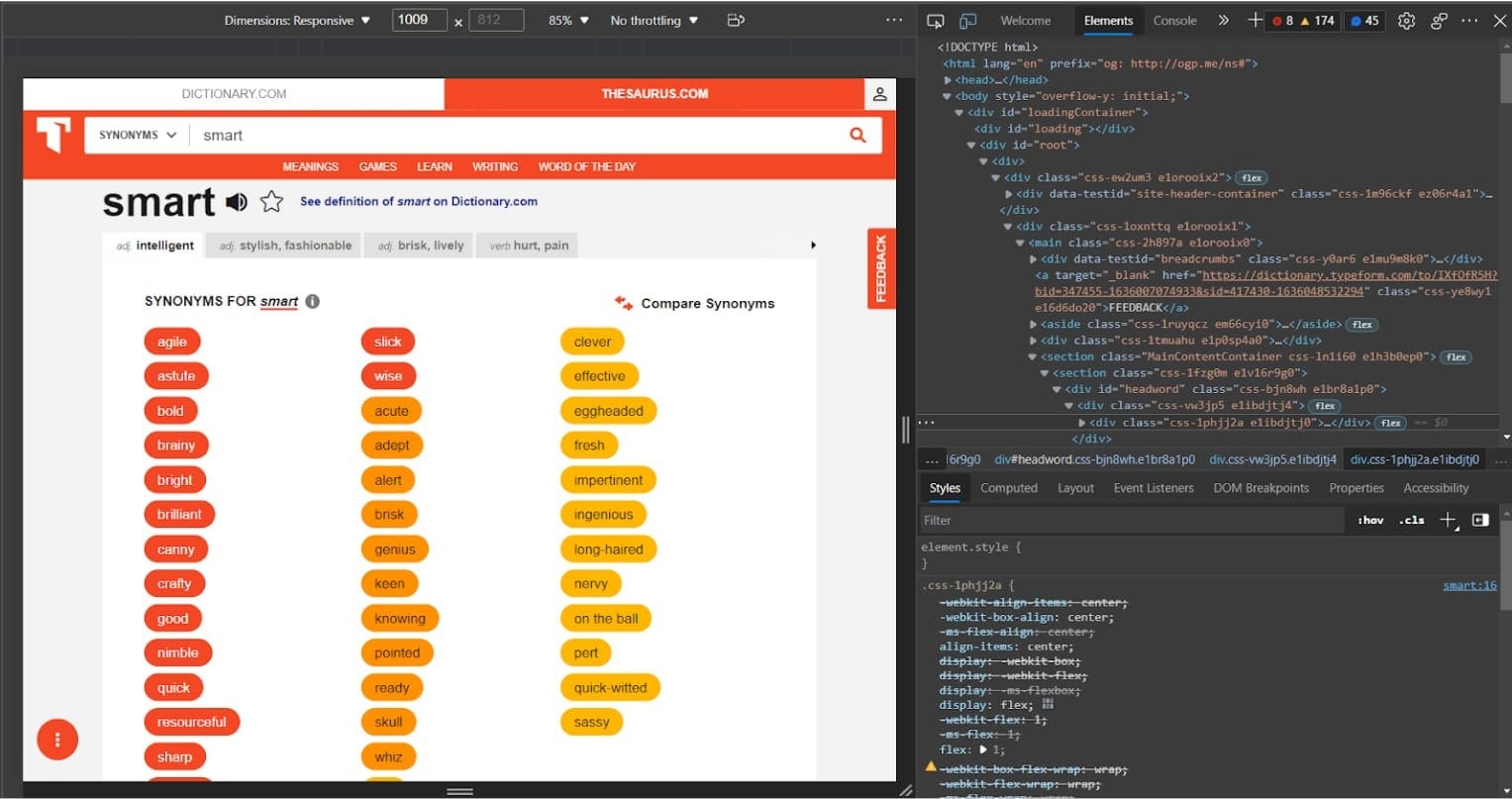
9.ต่อไปให้คลิกขวาที่องค์ประกอบ HTML ที่ไฮไลต์ซึ่งมีคำพ้องความหมายแรก แล้วคลิก “copy selector”
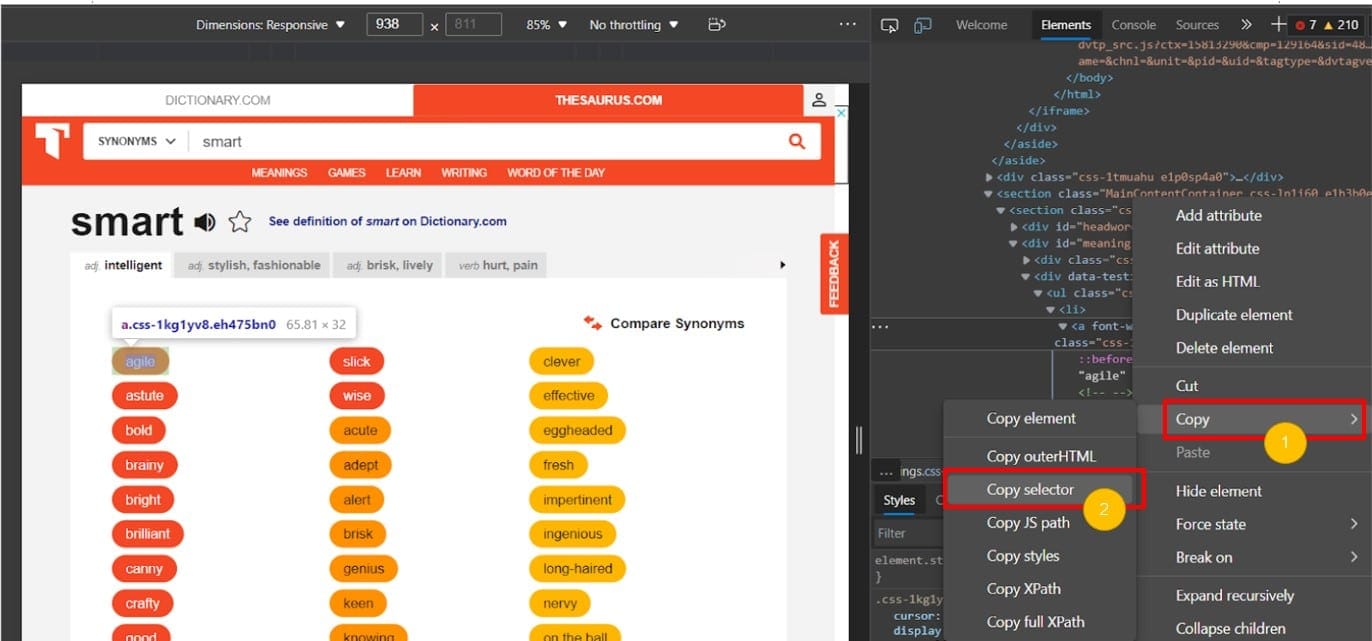
10.แล้วไปยังไฟล์ index.js ให้กำหนดตัวแปร “page” ไปที่ https://www.thesaurus.com/browse/smart ในอินสแตนซ์ของเบราว์เซอร์ที่สร้างขึ้นใหม่
11.ต่อไปกำหนดตัวแปร “element” โดยให้ page รอ element’s selector ที่ต้องการ ปรากฏใน DOM ของหน้าเว็บ
12.ข้อความใน element จะถูกดึงออกมาโดยใช้ฟังก์ชัน evaluate() และแสดงภายในตัวแปร “text” สุดท้ายก็ปิดอินสแตนซ์ของเบราว์เซอร์ โดยโค้ดจะเป็นดังนี้
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
await page.goto('https://www.thesaurus.com/browse/smart')
var element = await page.waitFor("#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(1) > a")
var text = await page.evaluate(element => element.textContent, element)
console.log(text)
browser.close()
}
scrape()
13.สามารถทดสอบสคริปต์ index.js โดยใช้คำสั่ง node index.js จะเห็นว่าสคริปต์ แสดงคำพ้องความหมายของคำว่า “smart” ตัวแรก

14.หากต้องการคำพ้องมากกว่าอันดับแรกเราสามารถใช้ for loop เข้ามาช่วยได้เช่น
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
await page.goto('https://www.thesaurus.com/browse/smart')
for(i = 1; i < 6; i++){
var element = await page.waitFor("#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(" + i + ") > a")
var text = await page.evaluate(element => element.textContent, element)
console.log(text)
}
browser.close()
}
scrape()
15.เสร็จแล้วก็สามารถลองรันด้วยคำสั่ง node index.js ได้เลยครับ
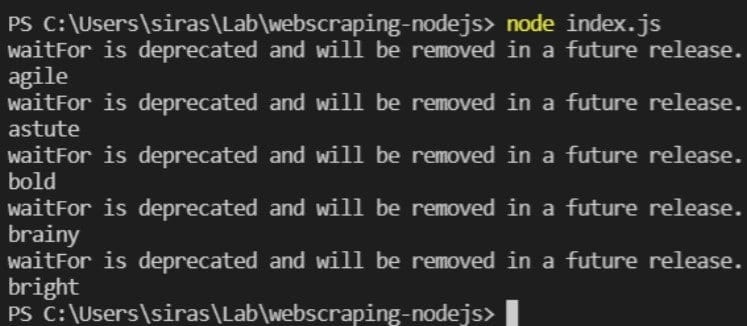
จะเห็นได้ว่าตอนนี้เราก็สามารถดึงข้อความหรือเนื้อหาจากเว็บได้แล้ว และการคัดลอกข้อมูลจากหน้าเว็บ จะเป็นอีกหนึ่งตัวช่วยในสร้างชุดข้อมูล (dataset) ที่อาจเป็นประโยชน์สำหรับการทำ Machine Learning การทำ Data Visualization หรือการวิเคราะห์ข้อมูล
ที่มา: Web Scraping in Node.js! – DEV Community


 เขียนโดย
เขียนโดย







